DeepSeek kembali menjadi sorotan.
Kali ini, ceritanya lebih besar daripada sekadar kartu model.
Dengan DeepSeek-V4-Pro Dan DeepSeek-V4-Flash, DeepSeek tidak hanya merilis keluarga model open-weight lainnya. Mereka mencoba menggabungkan tiga ide menjadi satu peluncuran sekaligus:
- sebuah model sumber terbuka unggulan yang dapat lebih dekat dengan sistem tertutup terdepan.
- varian yang lebih murah, lebih cepat, dan lebih mudah diterapkan dalam skala besar.
- Dan Konteks 1 juta token diposisikan bukan sebagai fitur mewah, melainkan lebih sebagai fitur standar praktis untuk beban kerja yang berat.
Dan itu penting, karena ini bukan pertama kalinya perusahaan tersebut memicu perhatian global terhadap AI.
Ketika siklus model DeepSeek sebelumnya menembus pasar utama pada Januari 2025, ia menjadi lebih dari sekadar peluncuran sumber terbuka lainnya. TechCrunch melaporkan bahwa DeepSeek naik ke peringkat tertentu. Peringkat No. 1 di App Store AS pada 26 Januari., setelah melompat dari Nomor 31 hanya beberapa hari sebelumnya, dan mencapai Total unduhan mencapai 2,6 juta di App Store dan Google Play. pada Senin pagi. Sehari kemudian, TechCrunch juga melaporkan bahwa aplikasi Android DeepSeek telah mencapai angka tersebut. Nomor 1 di Play Store AS, dengan perkiraan AppFigures lebih dari 1,2 juta unduhan di Play Store dan lebih dari 1,9 juta unduhan di App Store di seluruh dunia sejak diluncurkan.
Sejarah itu penting ketika melihat DeepSeek V4.
Alasan orang-orang kembali memperhatikan bukan hanya karena V4 memiliki Jendela konteks 1 juta token. Hal ini karena DeepSeek telah membuktikan bahwa mereka mampu keluar dari gelembung AI dan menjadi kisah arus utama global.
Rilis ini menunjukkan seberapa cepat AI sumber terbuka mempersempit kesenjangan dengan model tertutup yang ada saat ini — terutama dalam pengkodean, penalaran, dan alur kerja bergaya agen. Bagi tim yang membangun dengan AI, hal itu lebih penting daripada sekadar sensasi.
Mengapa Dunia Kembali Memperhatikan
Ada tiga alasan mengapa peluncuran ini mendapat perhatian langsung.
1. DeepSeek sudah memiliki sejarah yang sukses.
DeepSeek bukan lagi lab yang tidak dikenal. Siklus rilis sebelumnya menarik perhatian berbagai media seperti... TechCrunch, CNBC, Forbes, Fortune, The Verge, dan Business Insider — bukan hanya media yang dihasilkan AI.
Hal itu mengubah cara peluncuran model baru diinterpretasikan. Ketika merek AI yang sebelumnya viral meluncurkan rilis besar lainnya, orang-orang tidak membacanya sebagai "berita menarik." Mereka membacanya sebagai kemungkinan wabah gelombang kedua.
2. Rilis saat ini sudah menunjukkan sinyal daya tarik awal.
Saat peluncuran, secara resmi DeepSeek-V4-Pro Halaman di Hugging Face menunjukkan keterlibatan langsung yang kuat, termasuk basis pengikut yang besar untuk DeepSeek dan ratusan suka di halaman model dalam beberapa jam pertama setelah dirilis.
Yang tak kalah penting, pengecekan pencarian tepat setelah peluncuran menunjukkan sesuatu yang menarik: sudah ada penjelasan V4 baru, halaman arahan, dan ringkasan tolok ukur yang muncul di hasil pencarian — tetapi pada dasarnya Tidak ada hasil yang tersedia untuk "ulasan DeepSeek V4."“
Itu artinya perhatian datang lebih cepat daripada interpretasi berkualitas tinggi.
3. Narasi ini lebih besar daripada satu model.
DeepSeek V4 hadir di pasar yang sudah siap untuk kisah "open-source kembali mengejar ketertinggalan". Rilis baru ini sangat sesuai dengan narasi yang lebih luas tersebut: penalaran yang lebih baik, konteks yang lebih panjang, relevansi agen yang lebih tinggi, dan klaim efisiensi yang lebih kuat.
Itulah mengapa ini terasa lebih besar daripada peluncuran kartu model biasa.
Dua Model, Satu Strategi
Menurut siaran pers resmi Hugging Face, seri DeepSeek V4 mencakup dua model Mixture-of-Experts:
- DeepSeek-V4-Pro: 1,6T total parameter, 49B diaktifkan
- DeepSeek-V4-Flash: Total parameter 284B, 13B diaktifkan
Kedua model tersebut mendukung hingga 1 juta token konteks.
Hal ini penting karena DeepSeek tidak lagi hanya mengandalkan satu model.
Yang lebih menarik untuk dibaca adalah bahwa hal itu sedang membangun sebuah strategi produk dua lapis:
- Pro adalah produk unggulan, yang dirancang untuk bersaing memperebutkan perhatian dalam penalaran, pengkodean, pekerjaan konteks panjang, dan eksekusi bergaya agen.
- Kilatan adalah lapisan nilai, yang dirancang agar lebih kecil, lebih cepat, dan jauh lebih murah untuk penerapan yang lebih luas.
Pemisahan tersebut membuat peluncuran terasa lebih matang daripada rilis yang berfokus pada tolok ukur pada umumnya. Hal ini memberi pengembang dan tim pilihan realistis antara "kinerja terbaik" dan "efisiensi terbaik," alih-alih memaksakan kedua tujuan tersebut ke dalam satu model.
DeepSeek juga mengatakan bahwa V4 memperkenalkan beberapa peningkatan arsitektur yang dirancang untuk membuat inferensi konteks panjang lebih praktis, bukan hanya secara teoritis mungkin.
Ini termasuk:
- Arsitektur Perhatian Hibrida, menggabungkan Compressed Sparse Attention (CSA) dan Heavily Compressed Attention (HCA)
- Koneksi Hiper yang Dibatasi Manifold (mHC) untuk meningkatkan perambatan sinyal antar lapisan
- Pengoptimal muon untuk pelatihan yang lebih cepat dan stabil
Berdasarkan angka-angka yang dikeluarkan DeepSeek sendiri, DeepSeek-V4-Pro hanya menggunakan 27% FLOP inferensi token tunggal dan 10% cache KV yang dibutuhkan oleh DeepSeek-V3.2 dalam pengaturan 1 juta token..
Perbaikan seperti itulah yang membuat tim infrastruktur tertarik.
Ada juga kisah produk praktis di balik peluncurannya. Dokumentasi API resmi DeepSeek menunjukkan bahwa keduanya deepseek-v4-flash Dan deepseek-v4-pro tersedia melalui titik akhir yang kompatibel dengan OpenAI Dan Antropis format. Keduanya mendukung panggilan alat, keluaran JSON, dan panjang keluaran maksimum. 384 ribu token. Bagi para pengembang, hal ini penting karena membuat V4 lebih mudah diintegrasikan ke dalam aplikasi dan tumpukan agen yang sudah ada tanpa perlu penulisan ulang sepenuhnya.
Yang tak kalah penting, DeepSeek telah mengaitkan V4 dengan jalur migrasi. Nama model yang lebih lama obrolan pencarian mendalam Dan pencari-penalaran mendalam dijadwalkan akan dihentikan penggunaannya pada 2026/07/24, dengan pemetaan kompatibilitas yang menghubungkannya dengan mode non-berpikir dan berpikir dari deepseek-v4-flash.
Jadi, seberapa bagus DeepSeek V4 sebenarnya?
Jika kita mengesampingkan gembar-gembor dan melihat materi resminya, jawabannya adalah: DeepSeek V4 terlihat sangat kuat — terutama untuk pekerjaan konteks panjang, pengkodean, dan alur kerja yang banyak melibatkan penalaran — tetapi tetap harus dinilai sebagai pratinjau yang sangat menjanjikan dan bukan sebagai pemenang yang sepenuhnya mapan.
Itulah kerangka ulasan yang paling adil.
1. DeepSeek V4-Pro tampak seperti produk unggulan sumber terbuka yang serius.
Di atas kertas, DeepSeek-V4-Pro-Max Jelas sekali bahwa ini dimaksudkan untuk bersaing dengan model-model terdepan, bukan hanya rilis sumber terbuka lainnya.
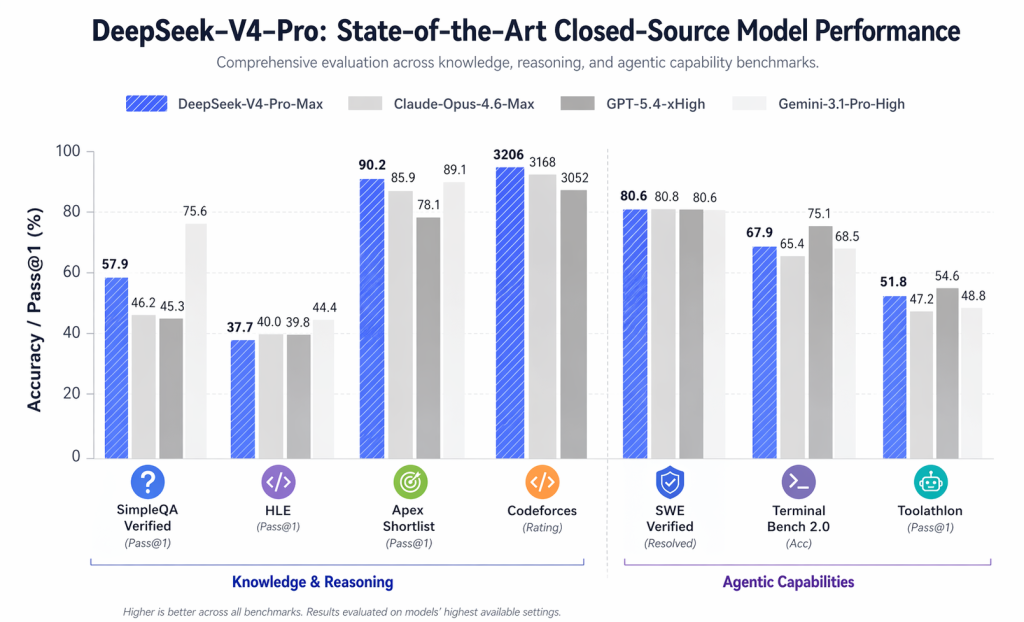
Dalam tabel perbandingan resmi, tercantum angka-angka penting seperti:
- LiveCodeBench: 93,5
- Peringkat Codeforces: 3206
- GPQA Diamond: 90.1
- Terverifikasi oleh SWE: 80,6
- MRCR 1M: 83,5
Kesimpulan yang lebih luas bukanlah bahwa DeepSeek V4 mengalahkan setiap model tertutup secara keseluruhan. Tidak demikian. Kesimpulan yang lebih kredibel adalah bahwa DeepSeek V4 kini layak diperhitungkan dalam sejumlah tugas teknis tingkat lanjut.
2. Flash mungkin menjadi kisah yang tak terduga.
Banyak perhatian akan tertuju pada varian Pro, tetapi DeepSeek-V4-Flash Pada akhirnya mungkin sama pentingnya secara komersial.
Menurut halaman harga API DeepSeek, V4-Flash dihargai sebagai berikut:
- $0.14 / 1M token input (cache miss)
- $0.028 / 1 juta token input (cache hit)
- $0.28 / 1M token keluaran
Sebagai perbandingan, DeepSeek-V4-Pro dibanderol dengan harga:
- $1.74 / 1 juta token input (cache miss)
- $0.145 / 1 juta token input (cache hit)
- $3.48 / 1M token keluaran
Hal itu menciptakan kisah produk yang lebih menarik daripada sekadar "model yang lebih besar menang". Flash memberi DeepSeek lapisan nilai yang realistis untuk kasus penggunaan bervolume tinggi, sementara Pro membawa posisi unggulan.
3. DeepSeek ingin memenangkan percakapan dengan agen, bukan hanya percakapan dengan chatbot.
Salah satu sinyal paling jelas dalam rilis V4 adalah apa yang DeepSeek pilih untuk ditekankan.
Tabel evaluasi resmi tidak hanya berhenti pada tolok ukur pengetahuan dan penalaran. Tabel tersebut juga menyoroti tugas yang berorientasi pada agen dan penggunaan alat seperti:
- Bangku Terminal 2.0
- Terverifikasi SWE
- SWE Pro
- Jelajahi Kompetitor
- MCPAtlas
- Perlombaan Alat
Hal itu penting karena menunjukkan bahwa DeepSeek ingin V4 dinilai sebagai sebuah keluarga model yang siap menjadi agen, bukan hanya sebagai chatbot atau asisten pemrograman.
Bagi tim yang membangun produk AI, ambisi tersebut lebih relevan daripada sekadar pertunjukan di papan peringkat.
4. Flash mungkin menjadi kisah yang tak terduga.
Banyak perhatian akan tertuju pada varian Pro, tetapi DeepSeek-V4-Flash Pada akhirnya mungkin sama pentingnya secara komersial.
Menurut halaman harga API DeepSeek, V4-Flash dihargai sebagai berikut:
- $0.14 / 1M token input (cache miss)
- $0.028 / 1 juta token input (cache hit)
- $0.28 / 1M token keluaran
Sebagai perbandingan, DeepSeek-V4-Pro dibanderol dengan harga:
- $1.74 / 1 juta token input (cache miss)
- $0.145 / 1 juta token input (cache hit)
- $3.48 / 1M token keluaran
Hal itu menciptakan kisah produk yang lebih menarik daripada sekadar "model yang lebih besar menang". Flash memberi DeepSeek lapisan nilai yang realistis untuk kasus penggunaan bervolume tinggi, sementara Pro membawa posisi unggulan.
5. Mode penalaran merupakan keunggulan nyata dalam hal kemudahan penggunaan.
DeepSeek V4 mendukung berbagai mode upaya penalaran yang berbeda, alih-alih memaksakan satu perilaku untuk setiap tugas.
Itu adalah keputusan produk yang bermakna.
Untuk permintaan rutin, pengguna dapat memprioritaskan kecepatan. Untuk tugas perencanaan, pengkodean, atau penelitian yang kompleks, mereka dapat mengalokasikan lebih banyak upaya penalaran. Dalam praktiknya, hal ini membuat keluarga model lebih mudah beradaptasi dengan beban kerja nyata daripada gaya inferensi statis tunggal.
6. Klaim terkuat adalah efisiensi konteks jangka panjang.
Banyak peluncuran AI membicarakan tentang durasi konteks. Namun, hanya sedikit yang membuat eksekusi konteks panjang terlihat masuk akal secara operasional.
Di sinilah V4 mungkin menjadi bagian yang paling menarik.
A Jendela konteks 1 juta token Ini sudah menjadi fitur utama, tetapi detail yang lebih penting adalah klaim DeepSeek bahwa V4-Pro hanya membutuhkan 27% dari FLOP inferensi token tunggal Dan 10% dari cache KV yang dibutuhkan oleh DeepSeek-V3.2 pada skala konteks tersebut.
Jika peningkatan tersebut terbukti efektif dalam praktiknya, hal itu bisa sama pentingnya dengan skor tolok ukur.
Mengapa Jendela Konteks 1 Juta Token Lebih Penting dari yang Terlihat?
Jendela konteks sejuta token bukan sekadar strategi pemasaran.
Secara praktis, ini berarti pengembang dan tim dapat memasukkan materi sumber dalam jumlah yang jauh lebih besar ke dalam satu sesi — basis kode yang panjang, kumpulan dokumentasi yang besar, arsip penelitian, transkrip pelanggan, atau alur kerja multi-file yang sebelumnya membutuhkan strategi pemecahan yang rumit.
Hal itu membuka beberapa peluang penggunaan yang bernilai tinggi:
1. Pemahaman kode program yang luas
Tim dapat menganalisis repositori yang lebih besar dengan lebih sedikit pemotongan manual, yang meningkatkan proses debugging, refactoring, dan alur kerja pengkodean berbasis agen.
2. Penelitian dan sintesis pengetahuan
Alih-alih meneruskan fragmen ke dalam model dan kehilangan konteks global, pengguna dapat bekerja dengan koleksi sumber yang jauh lebih besar dalam satu kali proses.
3. Agen AI yang lebih baik
Sistem agen bekerja lebih baik ketika mereka dapat menyimpan lebih banyak memori dalam konteks. Untuk perencanaan, penggunaan alat, dan eksekusi tugas multi-langkah, efisiensi konteks sama pentingnya dengan kualitas penalaran mentah.
4. Alur kerja dokumen perusahaan
Kontrak jangka panjang, dokumen kepatuhan, arsip dukungan, dan wiki internal menjadi lebih mudah dikelola dalam satu siklus penalaran.
Meskipun demikian, panjang konteks itu sendiri tidak bukan Menjamin kualitas. Banyak model mengiklankan jendela waktu yang lama tetapi kinerjanya menurun ketika kualitas pengambilan data, fokus memori, atau latensi menjadi masalah.
Itulah mengapa klaim efisiensi DeepSeek bisa dibilang lebih penting daripada angka 1 juta itu sendiri.
Mengapa Peluncuran Ini Terasa Lebih Besar dari Peluncuran Benchmark Biasa?
DeepSeek tidak memposisikan V4 hanya sebagai model konteks panjang.
Mereka juga melakukan upaya serius dalam pemikiran, pengkodean, Dan kinerja agen.
Siaran pers tersebut menyoroti hal-hal berikut: DeepSeek-V4-Pro-Max sebagai mode penalaran terkuat dalam jajaran tersebut, dan menempatkannya sebagai salah satu model sumber terbuka terbaik yang tersedia saat ini.
Berdasarkan tabel perbandingan yang dipublikasikan, V4-Pro-Max menunjukkan hasil yang sangat kuat di area seperti:
- LiveCodeBench
- Performa pengkodean ala Codeforces
- Berlian GPQA
- Jelajahi Kompetitor
- Tolok ukur rekayasa perangkat lunak ala SWE
- Tes konteks panjang seperti MRCR 1M dan CorpusQA 1M
Peringkat pastinya akan terus berubah seiring dengan pembaruan model oleh laboratorium setiap beberapa minggu. Namun sinyal strategisnya sudah jelas:
Model sumber terbuka semakin kredibel untuk alur kerja teknis yang serius, bukan hanya untuk kasus penggunaan obrolan ringan.
Itulah alasan sebenarnya mengapa peluncuran ini penting.
Bagian Paling Menarik: Mode Penalaran
DeepSeek V4 mendukung tiga mode upaya penalaran:
- Tidak berpikir untuk respons yang cepat dan ringan
- Berpikir Tinggi untuk analisis yang lebih lambat dan lebih teliti
- Pikirkan Max untuk upaya penalaran maksimal
Ini penting karena mencerminkan ke mana arah pasar model tersebut.
Masa depan bukan hanya tentang “satu model, satu perilaku.” Masa depan semakin berkaitan dengan... inferensi adaptif: Cepat saat Anda membutuhkan kecepatan, lebih dalam saat Anda membutuhkan akurasi.
Bagi tim produk, hal ini menciptakan keseimbangan yang lebih baik antara:
- latensi
- biaya
- kedalaman penalaran
- pengalaman pengguna
Dengan kata lain, DeepSeek tidak hanya mengirimkan sebuah model. Mereka mengirimkan sebuah pola penggunaan Hal itu sesuai dengan bagaimana produk AI yang sebenarnya berkembang.
Apa Artinya Ini bagi AI Sumber Terbuka?
DeepSeek V4 memperkuat tiga tren yang lebih luas.
1. Perangkat lunak sumber terbuka semakin sulit diabaikan.
Kesenjangan antara model terbuka dan tertutup terbaik masih nyata, tetapi semakin menyempit secara nyata. Setiap rilis utama kini memaksa tim produk untuk mengevaluasi kembali apakah mereka benar-benar membutuhkan model tertutup untuk setiap alur kerja.
2. Efisiensi menjadi medan pertempuran utama.
Model dengan skor tertinggi belum tentu merupakan model yang paling bermanfaat. Untuk implementasi nyata, efisiensi memori, throughput, dan biaya inferensi menentukan kelayakan produk.
3. Alur kerja agen meningkatkan standar.
Seiring semakin banyak perusahaan membangun agen AI, model yang paling berharga adalah model yang mampu menangani konteks panjang, penalaran multi-langkah, dan eksekusi berorientasi alat secara bersamaan.
DeepSeek V4 jelas membidik titik temu tersebut.
Beberapa Peringatan Sebelum Hype Menjadi Tak Terkendali
Ini adalah pratinjau rilis, Oleh karena itu, tim-tim harus tetap realistis.
Ada beberapa hal yang layak ditonton:
- Latensi dunia nyata di bawah beban konteks panjang yang berat.
- Konsistensi kinerja di berbagai gaya pemberian petunjuk
- Keandalan penggunaan alat di luar pengaturan standar.
- Kompleksitas penerapan untuk tim yang ingin menjalankannya secara lokal
- Apakah peningkatan tolok ukur akan menghasilkan hasil produksi yang lebih kuat?
DeepSeek juga mencatat bahwa penerapan lokal memerlukan alur kerja pengkodean dan inferensi tersendiri, bukan templat plug-and-play sederhana. Hal ini bukanlah masalah besar, tetapi berarti adopsi mungkin lebih mudah bagi tim yang memiliki keahlian teknis yang mumpuni daripada pengguna biasa.
Kesimpulan Akhir
DeepSeek V4 penting bukan hanya karena spesifikasinya, tetapi karena membuktikan bahwa DeepSeek mampu menarik perhatian global dalam skala besar.
Itulah mengapa industri ini kembali mengamati.
Dari sisi teknis, model ini menghadirkan jendela konteks 1 juta token, efisiensi konteks panjang yang lebih kuat, peningkatan kinerja pengkodean dan penalaran, serta pergeseran yang jelas menuju alur kerja bergaya agen.
Dari sisi pasar, DeepSeek hadir dengan momentum yang kuat. DeepSeek tidak lagi memulai dari nol. Mereka sudah memiliki pengakuan merek global dari terobosan sebelumnya, dan V4 diluncurkan ke pasar yang secara aktif mencari lompatan model terbuka yang kredibel berikutnya.
Jika Anda membangun aplikasi dengan AI, ini bukan sekadar rilis benchmark biasa. Ini adalah sinyal bahwa model open source semakin kompetitif, semakin praktis, dan semakin siap untuk digunakan dalam produksi nyata.
DeepSeek V4 mungkin tidak akan mengakhiri perdebatan antara sistem tertutup dan terbuka. Namun, DeepSeek V4 jelas meningkatkan standar harapan tim terhadap AI sumber terbuka di tahun 2026.
Cara Mencoba DeepSeek V4
Jika Anda ingin menjelajahinya sendiri, ada beberapa cara untuk memulainya:
- Jalankan secara lokal (kontrol penuh)
Unduh dan sebarkan melalui Hugging Face:
👉 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro - Coba langsung (tanpa pengaturan)
Gunakan antarmuka obrolan resmi:
👉 https://chat.deepseek.com/ - Integrasikan melalui API (bangun dengan menggunakan API tersebut)
Akses DeepSeek V4 melalui gateway API terpadu:
👉 https://www.imarouter.com Anda dapat dengan mudah mengintegrasikannya ke dalam alur kerja atau alat agen yang sudah ada seperti Cakar Terbuka, Kode Claude, dan sistem otomatisasi lainnya.
Sumber
- Halaman resmi model: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- TechCrunch: DeepSeek menggeser ChatGPT sebagai aplikasi teratas di App Store
- TechCrunch: DeepSeek mencapai peringkat No. 1 di Play Store AS
- CNBC: AI DeepSeek China menggulingkan ChatGPT di App Store: Inilah yang perlu Anda ketahui