DeepSeekが再び注目を集めている。.
今回は、単なるモデルカード以上の物語が展開される。.
と DeepSeek-V4-Pro そして DeepSeek-V4-Flash, DeepSeekは単に新たなオープンウェイトモデルファミリーをリリースするだけではありません。3つのアイデアを同時に1つの製品として発表しようとしています。
- 最先端の閉鎖型システムに近い位置づけが可能な、代表的なオープンソースモデル
- より安価で高速なバリアントで、大規模な展開も容易
- そして 1Mトークンコンテキスト 贅沢な機能というよりは、本格的なワークロードにおける実用的なデフォルト機能として位置づけられている。
そしてそれは重要なことだ。なぜなら、同社が世界的なAIの注目を集めたのは今回が初めてではないからだ。.
DeepSeekの初期モデルサイクルが2025年1月に主流になったとき、それは単なる別のオープンソースのローンチ以上のものとなった。TechCrunchはDeepSeekが 1月26日に米国のApp Storeで1位を獲得, ジャンプした後 31番はほんの数日前に, 、そして到達した App StoreとGoogle Playを合わせたダウンロード数は260万件。 月曜日の朝までに。その翌日、TechCrunchもDeepSeekのAndroidアプリが アメリカのPlayストアで1位, AppFiguresの推定によると Playストアでのダウンロード数は120万回以上、App Storeでのダウンロード数は190万回以上 発売以来、世界中で展開されている。.
その歴史は、 DeepSeek V4.
人々が再び注目している理由は、V4に 100万トークンのコンテキストウィンドウ. なぜなら、DeepSeekは既にAIバブルを突破し、世界的な主流の話題になることができることを証明しているからだ。.
今回のリリースは、オープンソースAIが最先端のクローズドモデルとの差をいかに急速に縮めているかを示しています。特にコーディング、推論、エージェント型ワークフローの分野で顕著です。AI開発チームにとって、これは単なる誇大広告よりもはるかに重要な意味を持ちます。.
世界が再び注目している理由
今回の発売がすぐに注目を集めている理由は3つあります。.
1. DeepSeekは既にブレイクアウトの実績がある
DeepSeekはもはや無名の研究所ではない。前回のリリースサイクルでは、次のようなメディアで取り上げられた。 TechCrunch、CNBC、Forbes、Fortune、The Verge、Business Insider ―AIネイティブメディアに限った話ではない。.
これにより、新モデルの発表に対する見方が変わる。以前に大きな話題を呼んだAIブランドが新たな主要モデルをリリースしても、人々はそれを「興味深いニュース」とは捉えない。むしろ、第二波の到来を予感させるものとして捉えるのだ。.
2. 現在のリリースは既に初期段階の好調な兆候を示している
発売時には、公式 DeepSeek-V4-Pro Hugging Faceのページは、公開後すぐに大きな反響を呼び、DeepSeekのフォロワー数も多く、モデルページには公開後数時間以内に数百件の「いいね!」がついた。.
同様に重要なことに、ローンチ直後の検索チェックで興味深いことが分かりました。検索結果にはすでに新しいV4の説明記事、ランディングページ、ベンチマーク概要が表示されていましたが、 「DeepSeek V4 レビュー」に関する検索結果は見つかりませんでした。“
つまり、質の高い通訳よりも早く人々の注目を集めているということだ。.
3. 物語は一つのモデルよりも大きい
DeepSeek V4は、「オープンソースが再び追いついてきた」というストーリーが既に展開されている市場に投入されます。この新バージョンは、より優れた推論、より長いコンテキスト、エージェントの関連性の向上、そしてより強力な効率性といった点で、まさにその大きな流れに合致しています。.
だからこそ、これは通常のモデルカードのリリースよりも大きな出来事のように感じられるのです。.
2つのモデル、1つの戦略
Hugging Faceの公式発表によると、DeepSeek V4シリーズには2つのMixture-of-Expertsモデルが含まれています。
- DeepSeek-V4-Pro: 合計パラメータ数 1.6T、有効パラメータ数 49B
- DeepSeek-V4-Flash合計パラメータ数:284B、有効パラメータ数:13B
両モデルともサポートしています 最大100万トークンのコンテキスト.
これは重要な点です。なぜなら、DeepSeekはもはや単一モデルの物語を語っているわけではないからです。.
より興味深い読み物は、 2層構造の製品戦略:
- プロ は、推論、コーディング、長期コンテキスト処理、エージェント型実行において注目を集めることを目指して設計されたフラッグシップモデルです。
- フラッシュ バリューレイヤーは、より小規模で高速、かつ低コストで、より広範な展開を可能にするように設計されています。
この分割によって、今回のリリースは、一般的なベンチマーク重視のリリースよりも成熟した印象を与える。開発者やチームは、「最高のパフォーマンス」と「最高の効率性」という2つの目標を1つのモデルに押し込めるのではなく、どちらか一方を現実的に選択できる。.
DeepSeekはまた、V4では、長コンテキスト推論を理論的に可能なだけでなく、より実用的なものにするために設計された、いくつかのアーキテクチャ上のアップグレードが導入されていると述べている。.
これらには以下が含まれます。
- ハイブリッドアテンションアーキテクチャ, 圧縮スパースアテンション(CSA)と高圧縮アテンション(HCA)を組み合わせたもの
- 多様体制約付きハイパーコネクション(mHC) 層間の信号伝搬を改善する
- ミューオン最適化ツール より速く、より安定したトレーニングのために
DeepSeek自身のデータによると、, DeepSeek-V4-Proは、1Mトークン設定において、DeepSeek-V3.2が必要とするシングルトークン推論FLOPsのうち27%、KVキャッシュのうち10%のみを使用します。.
そういった改善こそ、インフラチームの関心を引くものだ。.
また、発売の背後には実用的な製品ストーリーもある。DeepSeekの公式APIドキュメントには、 deepseek-v4-flash そして deepseek-v4-pro 互換性のあるエンドポイントを通じて利用可能です オープンAI そして 人類学的 フォーマット。どちらもツール呼び出し、JSON出力、最大出力長をサポートしています。 384,000トークン. 開発者にとってこれは重要な点です。なぜなら、V4を既存のアプリケーションやエージェントスタックに、全面的な書き換えなしに容易に組み込むことができるようになるからです。.
同様に重要な点として、DeepSeekはすでにV4を移行パスに結び付けています。 ディープシークチャット そして ディープシーク推論器 は、以下の日付で廃止される予定です。 2026/07/24, 互換性により、それらを非思考モードと思考モードにマッピングします。 deepseek-v4-flash.
では、DeepSeek V4は実際どれほど優れているのでしょうか?
誇張表現を取り除いて公式資料を見てみると、答えは次のようになります。 DeepSeek V4は、特に長文コンテキストの処理、コーディング、推論を多用するワークフローにおいて、非常に強力なツールに見えるが、完全に決定的な勝者というよりは、非常に有望なプレビュー版として評価されるべきだろう。.
それが最も公平な評価方法だ。.
1. DeepSeek V4-Proは本格的なオープンソースのフラッグシップモデルのようだ
書類上は、, DeepSeek-V4-Pro-Max これは明らかに、他のオープンソース製品だけでなく、最先端のモデルとも競合することを意図している。.
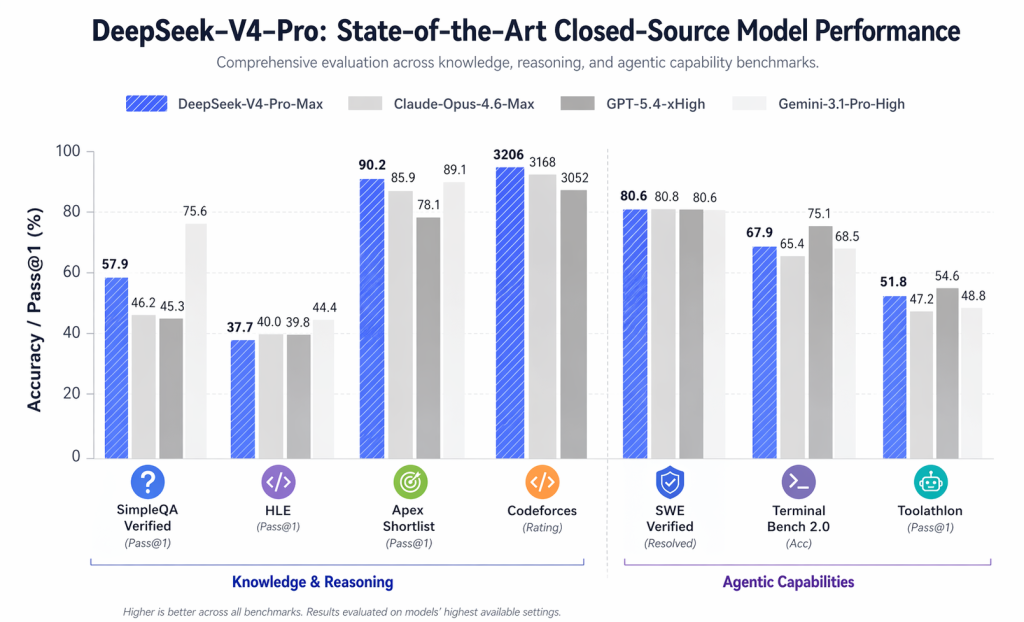
公式比較表には、次のような注目すべき数値が掲載されています。
- LiveCodeBench: 93.5
- Codeforcesレーティング:3206
- GPQAダイヤモンド:90.1
- SWE検証済み:80.6
- MRCR 1M: 83.5
より重要な点は、DeepSeek V4があらゆるクローズドモデルを凌駕するということではありません。そうではありません。より妥当な結論は、DeepSeek V4が多くの高度な技術的タスクにおいて、他のクローズドモデルと同等の有力な選択肢として議論されるべき存在になったということです。.
2. フラッシュは隠れた逸材かもしれない
Pro版には多くの注目が集まるだろうが、 DeepSeek-V4-Flash 商業的に見ても、最終的には同じくらい重要になるかもしれない。.
DeepSeekのAPI価格ページによると、V4-Flashの価格は以下のとおりです。
- $0.14 / 1M 入力トークン (キャッシュミス)
- $0.028 / 1M入力トークン(キャッシュヒット)
- $0.28 / 1M 出力トークン
それに比べて、, DeepSeek-V4-Pro 価格は以下の通りです。
- $1.74 / 1M入力トークン(キャッシュミス)
- $0.145 / 1M入力トークン(キャッシュヒット)
- $3.48 / 1M 出力トークン
これにより、「大型モデルが勝つ」という単純な構図よりも、より興味深い製品ストーリーが生まれます。Flashは、DeepSeekに大量利用の場面で現実的な価値を提供するレイヤーを与え、一方Proはフラッグシップモデルとしての地位を確立します。.
3. DeepSeekは、チャットボットとの会話だけでなく、エージェントとの会話でも勝利を目指している。
V4リリースで最も明確なシグナルの1つは、DeepSeekが何を強調しようとしているかということだ。.
公式の評価表は、知識と推論のベンチマークにとどまらず、さらに以下の点を強調している。 主体性およびツール使用指向のタスク のような:
- ターミナルベンチ 2.0
- SWE検証済み
- SWE Pro
- BrowseComp
- MCPAtlas
- ツールアスロン
これは重要です。なぜなら、DeepSeekがV4を エージェント対応モデルファミリー, チャットボットやコーディングアシスタントとしてだけでなく。.
AI製品を開発するチームにとって、それは単なるランキング上位を目指すことよりも、はるかに意義のある目標だ。.
4. フラッシュは隠れた逸材かもしれない
Pro版には多くの注目が集まるだろうが、 DeepSeek-V4-Flash 商業的に見ても、最終的には同じくらい重要になるかもしれない。.
DeepSeekのAPI価格ページによると、V4-Flashの価格は以下のとおりです。
- $0.14 / 1M 入力トークン (キャッシュミス)
- $0.028 / 1M入力トークン(キャッシュヒット)
- $0.28 / 1M 出力トークン
それに比べて、, DeepSeek-V4-Pro 価格は以下の通りです。
- $1.74 / 1M入力トークン(キャッシュミス)
- $0.145 / 1M入力トークン(キャッシュヒット)
- $3.48 / 1M 出力トークン
これにより、「大型モデルが勝つ」という単純な構図よりも、より興味深い製品ストーリーが生まれます。Flashは、DeepSeekに大量利用の場面で現実的な価値を提供するレイヤーを与え、一方Proはフラッグシップモデルとしての地位を確立します。.
5. 推論モードは、実用性において大きな利点となる。
DeepSeek V4は、タスクごとに単一の動作を強制するのではなく、さまざまな推論努力モードをサポートします。.
それは重要な製品決定だ。.
定型的なリクエストの場合、ユーザーは速度を優先できます。複雑な計画、コーディング、または調査タスクの場合は、推論処理により多くのリソースを割り当てることができます。実際には、これにより、単一の静的な推論スタイルよりも、モデルファミリーは実際のワークロードに対してより適応しやすくなります。.
6. 最も有力な主張は、長期コンテキスト効率性である。
多くのAI関連の発表ではコンテキストの長さが強調されるが、長コンテキストの実行が運用上現実的であることを示すものは少ない。.
V4が最も興味深いのはまさにこの点かもしれない。.
あ 100万トークンのコンテキストウィンドウ すでに注目の機能となっているが、より重要な詳細は、DeepSeek が V4-Pro には 単一トークン推論のFLOPsは27% そして KVキャッシュの10% DeepSeek-V3.2では、そのコンテキストスケールで必要となります。.
もしそうした成果が実際に維持されるなら、それはベンチマークスコアと同じくらい重要な意味を持つ可能性がある。.
100万トークンのコンテキストウィンドウが、想像以上に重要な理由
100万トークンのコンテキストウィンドウは、単なるマーケティング上の宣伝文句ではない。.
実際には、これは開発者やチームが、従来は扱いにくい分割戦略を必要としていた、長大なコードベース、膨大なドキュメントセット、研究アーカイブ、顧客とのやり取りの記録、あるいは複数ファイルからなるワークフローなど、はるかに大量のソース素材を単一のセッションに投入できることを意味します。.
これにより、いくつかの高価値なユースケースが生まれます。
1. 大規模コードベースの理解
チームは、より少ない手作業によるスライスで大規模なリポジトリを分析できるようになり、デバッグ、リファクタリング、およびエージェントベースのコーディングワークフローが改善されます。.
2. 研究と知識の統合
断片をモデルに渡してグローバルなコンテキストを失う代わりに、ユーザーはより大規模なソースコレクションを一度に扱うことができる。.
3. より優れたAIエージェント
エージェントシステムは、コンテキストに多くのメモリを保持できるほどパフォーマンスが向上します。計画立案、ツールの使用、複数ステップのタスク実行においては、コンテキストの効率性は、推論能力そのものと同じくらい重要です。.
4. 企業向け文書ワークフロー
長期契約書、コンプライアンス文書、サポートアーカイブ、社内Wikiなどは、一つの論理ループ内でより効率的に管理できるようになる。.
とはいえ、文脈の長さだけでは ない 品質を保証する。多くのモデルは長時間のウィンドウ表示を謳っているが、検索品質、メモリフォーカス、またはレイテンシに問題が生じると性能が低下する。.
だからこそ、DeepSeekの効率性に関する主張は、100万という数字そのものよりも重要と言えるだろう。.
今回のローンチが通常のベンチマーク低下よりも大きく感じられる理由
DeepSeekはV4を単なる長文コンテキストモデルとして位置付けているわけではない。.
また、 推論, コーディング、 そして 主体的なパフォーマンス.
リリース内容のハイライト DeepSeek-V4-Pro-Max ラインナップの中で最も強力な推論モードとして位置づけ、現在入手可能な最高のオープンソースモデルの一つとして位置づけている。.
公開されている比較表全体を通して、V4-Pro-Maxは特に次のような分野で優れた結果を示しています。
- LiveCodeBench
- Codeforcesスタイルのコーディングパフォーマンス
- GPQAダイヤモンド
- BrowseComp
- SWEスタイルのソフトウェアエンジニアリングベンチマーク
- MRCR 1MやCorpusQA 1Mのような長文コンテキストテスト
研究所が数週間ごとにモデルを更新するため、正確なランキングは今後も変動するだろう。しかし、戦略的なシグナルはすでに明確だ。
オープンソースモデルは、軽量なチャット用途だけでなく、本格的な技術ワークフローにおいても、ますます信頼性を高めている。.
それが、今回の打ち上げが重要な本当の理由です。.
最も興味深い部分:推論モード
DeepSeek V4は、3つの推論実行モードをサポートしています。
- 思考停止 高速で軽量なレスポンスを実現
- 高みを目指せ よりゆっくりとした、より慎重な分析のために
- マックスを考えてみよう 最大限の推論努力のために
これは、模型市場の今後の方向性を反映しているため、重要な意味を持つ。.
未来は「一つのモデル、一つの行動」だけではありません。 適応推論スピードが必要な時は速く、正確さが必要な時は深く。.
製品開発チームにとって、これは以下の点においてより良いバランスを生み出します。
- レイテンシー
- 料金
- 推論の深さ
- ユーザーエクスペリエンス
言い換えれば、DeepSeekは単にモデルを出荷しているだけではない。 使用パターン これは、実際のAI製品の進化の仕方と一致している。.
オープンソースAIにとってこれは何を意味するのか
DeepSeek V4は、より広範な3つの傾向をさらに強化する。.
1. オープンソースは無視できない存在になりつつある
オープンモデルとクローズドモデルの間のギャップは依然として存在するものの、目に見える形で縮小しつつある。現在では、メジャーリリースごとに、製品チームはすべてのワークフローに本当にクローズドモデルが必要なのかどうかを再評価せざるを得なくなっている。.
2. 効率性は一流の戦場になりつつある
スコアが最も高いモデルが、必ずしも最も有用なモデルとは限りません。実際の導入においては、メモリ効率、スループット、推論コストが製品の実現可能性を左右します。.
3. エージェントのワークフローは基準を引き上げている
AIエージェントを開発する企業が増えるにつれ、最も価値のあるモデルは、長いコンテキスト、複数ステップの推論、およびツール指向の実行を同時に処理できるモデルとなる。.
DeepSeek V4は明らかにその交差点を目指している。.
過熱が制御不能になる前に注意すべき点
これは プレビューリリース, だから、チームは現実的な姿勢を保つべきだ。.
注目すべき点がいくつかあります。
- 長時間のコンテキスト負荷がかかった場合の実際のレイテンシ
- 異なるプロンプトスタイル間でのパフォーマンスの一貫性
- ベンチマーク設定外におけるツール使用の信頼性
- ローカルで実行したいチームにとってのデプロイメントの複雑さ
- ベンチマークの向上は、より強力な生産成果につながるのか
DeepSeekはまた、ローカル展開には、単純なプラグアンドプレイのテンプレートではなく、独自のエンコードおよび推論ワークフローが必要であると指摘している。これは致命的な欠点ではないが、技術的に成熟したチームの方が、一般ユーザーよりも導入しやすい可能性があることを意味する。.
最終的な見解
DeepSeek V4が重要なのは、そのスペックだけでなく、DeepSeekが大規模に世界的な注目を集めることができることを証明しているからである。.
だからこそ、業界は再び注目しているのだ。.
技術面では、このモデルは100万トークンのコンテキストウィンドウ、より強力なロングコンテキスト効率、改善されたコーディングおよび推論性能、そしてエージェントスタイルのワークフローへの明確な移行によって前進している。.
市場面では、勢いに乗って登場する。DeepSeekはもはやゼロからのスタートではない。前回のブレイクスルーで既に世界的なブランド認知度を獲得しており、V4は次なる信頼できるオープンモデルの飛躍を積極的に求めている市場に投入される。.
AIを活用した開発に取り組んでいる方にとって、これは単なるベンチマークのリリースではありません。オープンモデルがより競争力を高め、より実用的になり、実際の運用環境での利用にますます適したものになっていることを示すシグナルなのです。.
DeepSeek V4は、クローズドソース対オープンソースの議論に終止符を打つものではないかもしれない。しかし、2026年にチームがオープンソースAIに期待すべき水準を確実に引き上げたと言えるだろう。.
DeepSeek V4 の試用方法
自分で調べてみたい場合は、始めるためのいくつかの方法があります。
- ローカルで実行(完全な制御権)
Hugging Face経由でダウンロードしてデプロイする:
👉 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro - すぐに試せます(設定不要)
公式チャットインターフェースを使用してください。
👉 https://chat.deepseek.com/ - API経由で統合する(APIを使用して構築する)
統合APIゲートウェイ経由でDeepSeek V4にアクセスします。
👉 https://www.imarouter.com 既存のワークフローやエージェントツールに簡単に組み込むことができます。 オープンクロー, クロード・コード, およびその他の自動化システム。.
情報源
- 公式モデルページ:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- TechCrunch:DeepSeekがChatGPTを抜いてApp Storeのトップアプリに
- TechCrunch:DeepSeekが米国のPlayストアで1位を獲得
- CNBC:中国のDeepSeek AIがApp StoreでChatGPTを抜き、トップに躍り出る:知っておくべきこと