DeepSeek vuelve a estar en el punto de mira.
Esta vez, la historia es más importante que una simple tarjeta modelo.
Con DeepSeek-V4-Pro y Flash DeepSeek-V4, DeepSeek no solo está lanzando otra familia de modelos de peso abierto. Está intentando convertir tres ideas en un solo lanzamiento al mismo tiempo:
- un modelo insignia de código abierto que puede estar más cerca de los sistemas cerrados de vanguardia
- Una variante más económica y rápida, más fácil de implementar a gran escala.
- y Contexto de 1 millón de tokens Se presenta menos como una característica de lujo y más como una opción práctica por defecto para cargas de trabajo exigentes.
Y eso es importante, porque no es la primera vez que la empresa ha atraído la atención mundial en el ámbito de la inteligencia artificial.
Cuando el ciclo de modelos anterior de DeepSeek irrumpió en el mercado general en enero de 2025, se convirtió en mucho más que otro lanzamiento de código abierto. TechCrunch informó que DeepSeek ascendió a Número 1 en la App Store de EE. UU. el 26 de enero., después de saltar desde El número 31 apenas un par de días antes, y alcanzó 2,6 millones de descargas combinadas en la App Store y Google Play. para el lunes por la mañana. Un día después, TechCrunch también informó que la aplicación de Android de DeepSeek alcanzó Número 1 en la Play Store de EE. UU., con AppFigures estimando Más de 1,2 millones de descargas en Play Store y más de 1,9 millones de descargas en App Store. en todo el mundo desde su lanzamiento.
Esa historia importa cuando se mira DeepSeek V4.
La razón por la que la gente vuelve a prestar atención no es solo porque V4 tiene un Ventana de contexto de 1 millón de tokens. Esto se debe a que DeepSeek ya ha demostrado que puede salir de la burbuja de la IA y convertirse en una noticia de interés mundial.
Este lanzamiento demuestra la rapidez con la que la IA de código abierto está reduciendo la brecha con los modelos cerrados de vanguardia, especialmente en codificación, razonamiento y flujos de trabajo basados en agentes. Para los equipos que desarrollan con IA, esto es más importante que la publicidad.
¿Por qué el mundo vuelve a estar mirando?
Hay tres razones por las que este lanzamiento está recibiendo atención inmediata.
1. DeepSeek ya tiene un historial de éxitos rotundos.
DeepSeek ya no es un laboratorio desconocido. Su ciclo de lanzamiento anterior atrajo la atención de medios como TechCrunch, CNBC, Forbes, Fortune, The Verge y Business Insider — no solo los medios de comunicación nativos de la IA.
Eso cambia la forma en que se interpreta el lanzamiento de un nuevo modelo. Cuando una marca de IA que ya se había vuelto viral lanza otra versión importante, la gente no lo interpreta como una "noticia interesante", sino como un posible repunte de la popularidad.
2. La versión actual ya muestra señales iniciales de buena acogida.
En el lanzamiento, el oficial DeepSeek-V4-Pro La página de Hugging Face mostró una fuerte interacción inmediata, incluyendo una gran base de seguidores para DeepSeek y cientos de "me gusta" en la página del modelo durante las primeras horas de su lanzamiento.
Igualmente importante, una comprobación de búsqueda justo después del lanzamiento reveló algo interesante: ya aparecían en la búsqueda explicaciones, páginas de destino y resúmenes de pruebas comparativas recientes de V4, pero esencialmente No se encontraron resultados para la búsqueda "Reseña de DeepSeek V4".“
Eso significa que la atención llega más rápido que la interpretación de alta calidad.
3. La narrativa es más amplia que un solo modelo.
DeepSeek V4 llega a un mercado que ya está preparado para la historia de que el software de código abierto está recuperando terreno. Esta nueva versión encaja perfectamente en esa narrativa más amplia: mejor razonamiento, contexto más extenso, mayor relevancia de los agentes y afirmaciones más contundentes sobre su eficiencia.
Por eso, esto parece más importante que el lanzamiento de una tarjeta modelo normal.
Dos modelos, una estrategia
Según el comunicado oficial de Hugging Face, la serie DeepSeek V4 incluye dos modelos Mixture-of-Experts:
- DeepSeek-V4-Pro: 1,6 T parámetros totales, 49 B activados
- Flash DeepSeek-V4: 284B parámetros totales, 13B activados
Ambos modelos son compatibles hasta 1 millón de tokens de contexto.
Esto es importante porque DeepSeek ya no cuenta una historia basada en un solo modelo.
Lo más interesante es que está construyendo un estrategia de producto de dos capas:
- Pro es el producto estrella, diseñado para competir por la atención en razonamiento, codificación, trabajo de contexto extenso y ejecución de estilo agente.
- Destello es la capa de valor, diseñada para ser más pequeña, más rápida y mucho más barata para una implementación más amplia
Esa distinción hace que el lanzamiento se sienta más maduro que un lanzamiento típico centrado en pruebas de rendimiento. Ofrece a los desarrolladores y equipos una opción realista entre "mejor rendimiento" y "mejor eficiencia", en lugar de forzar ambos objetivos en un solo modelo.
DeepSeek también afirma que la versión 4 introduce varias mejoras arquitectónicas diseñadas para hacer que la inferencia de contexto extenso sea más práctica, no solo teóricamente posible.
Estos incluyen:
- Arquitectura de atención híbrida, combinando Atención Dispersa Comprimida (CSA) y Atención Altamente Comprimida (HCA)
- Hiperconexiones con restricciones de variedad (mHC) para mejorar la propagación de la señal a través de las capas
- optimizador de muones para un entrenamiento más rápido y estable
Según las propias cifras de DeepSeek, DeepSeek-V4-Pro utiliza solo 27% de los FLOPs de inferencia de un solo token y 10% de la caché KV requerida por DeepSeek-V3.2 en una configuración de 1 millón de tokens..
Ese es el tipo de mejora que despierta el interés de los equipos de infraestructura.
También hay una historia práctica del producto detrás del lanzamiento. La documentación oficial de la API de DeepSeek muestra que ambos deepseek-v4-flash y deepseek-v4-pro están disponibles a través de puntos finales compatibles con OpenAI y Antrópico formatos. Ambos admiten llamadas a herramientas, salida JSON y una longitud máxima de salida de 384.000 tokens. Para los desarrolladores, esto es importante porque facilita la integración de V4 en las aplicaciones y pilas de agentes existentes sin necesidad de una reescritura completa.
Igualmente importante, DeepSeek ya ha vinculado V4 a una ruta de migración. Los nombres de modelos más antiguos chat de búsqueda profunda y Razonador de búsqueda profunda Se prevé que se desactiven en 2026/07/24, con compatibilidad que los mapea a los modos de pensamiento y no pensamiento de deepseek-v4-flash.
Entonces, ¿qué tan bueno es realmente DeepSeek V4?
Si dejamos de lado la publicidad y nos fijamos en el material oficial, la respuesta es: DeepSeek V4 parece realmente potente, especialmente para trabajos con contextos extensos, codificación y flujos de trabajo con gran carga de razonamiento, pero aún debe considerarse una versión preliminar muy prometedora en lugar de un producto totalmente consolidado.
Esa es la forma más justa de plantear la reseña.
1. DeepSeek V4-Pro parece un buque insignia de código abierto de gran envergadura.
En teoría, DeepSeek-V4-Pro-Max Está claro que pretende competir con los modelos de vanguardia, no solo con otros lanzamientos de código abierto.
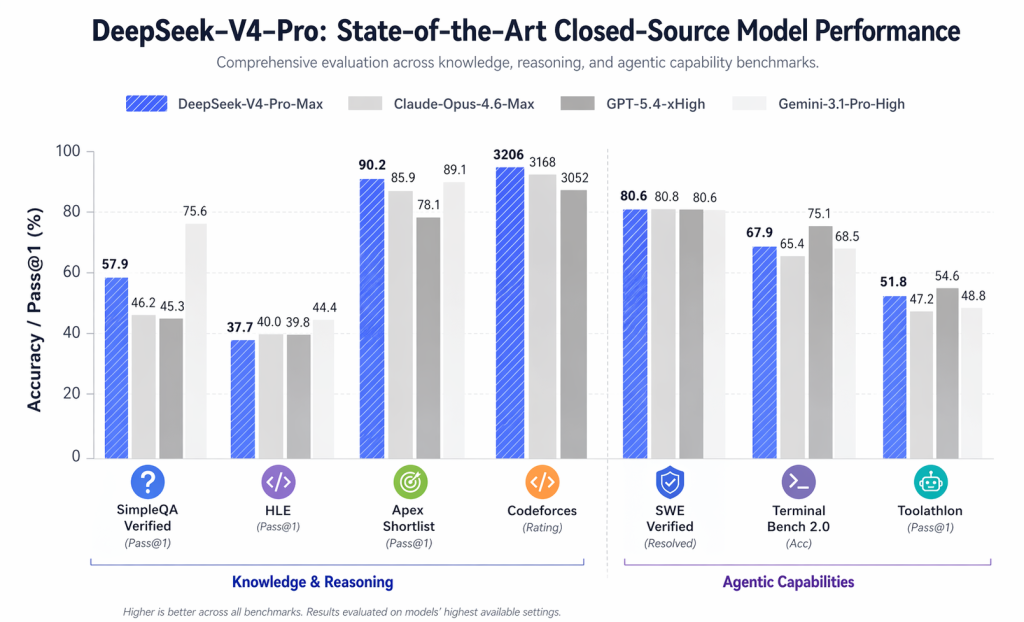
En la tabla comparativa oficial, se muestran cifras notables como:
- LiveCodeBench: 93,5
- Calificación de Codeforces: 3206
- GPQA Diamante: 90,1
- SWE verificado: 80.6
- MRCR 1M: 83,5
La conclusión principal no es que DeepSeek V4 supere a todos los modelos cerrados en todos los aspectos. No es así. La conclusión más plausible es que ahora merece estar entre las opciones más importantes para diversas tareas técnicas avanzadas.
2. Flash podría ser la historia oculta.
Se prestará mucha atención a la variante Pro, pero Flash DeepSeek-V4 Puede que acaben siendo igual de importantes desde el punto de vista comercial.
Según la página de precios de la API de DeepSeek, V4-Flash tiene el siguiente precio:
- $0.14 / 1M tokens de entrada (fallo de caché)
- $0.028 / 1M tokens de entrada (acierto de caché)
- $0.28 / 1M tokens de salida
En comparación, DeepSeek-V4-Pro tiene un precio de:
- $1.74 / 1M tokens de entrada (fallo de caché)
- $0.145 / 1M tokens de entrada (acierto de caché)
- $3.48 / 1M tokens de salida
Eso crea una historia de producto más interesante que la de "el modelo más grande gana". Flash le da a DeepSeek una capa de valor realista para casos de uso de alto volumen, mientras que Pro mantiene el posicionamiento de producto estrella.
3. DeepSeek quiere ganar la conversación con los agentes, no solo la conversación con los chatbots.
Una de las señales más claras de la versión V4 es lo que DeepSeek decide destacar.
Las tablas de evaluación oficiales no se limitan a los puntos de referencia de conocimiento y razonamiento. También destacan tareas orientadas a la agencia y al uso de herramientas como:
- Banco terminal 2.0
- Verificado por SWE
- SWE Pro
- BrowseComp
- Atlas de MCPA
- Toolathlon
Eso importa porque sugiere que DeepSeek quiere que V4 sea juzgado como un Familia de modelos listos para agentes, no solo como chatbot o asistente de programación.
Para los equipos que desarrollan productos de IA, esa es una ambición más relevante que el mero espectáculo de las clasificaciones.
4. Flash podría ser la historia oculta.
Se prestará mucha atención a la variante Pro, pero Flash DeepSeek-V4 Puede que acaben siendo igual de importantes desde el punto de vista comercial.
Según la página de precios de la API de DeepSeek, V4-Flash tiene el siguiente precio:
- $0.14 / 1M tokens de entrada (fallo de caché)
- $0.028 / 1M tokens de entrada (acierto de caché)
- $0.28 / 1M tokens de salida
En comparación, DeepSeek-V4-Pro tiene un precio de:
- $1.74 / 1M tokens de entrada (fallo de caché)
- $0.145 / 1M tokens de entrada (acierto de caché)
- $3.48 / 1M tokens de salida
Eso crea una historia de producto más interesante que la de "el modelo más grande gana". Flash le da a DeepSeek una capa de valor realista para casos de uso de alto volumen, mientras que Pro mantiene el posicionamiento de producto estrella.
5. Los modos de razonamiento representan una verdadera ventaja en cuanto a usabilidad.
DeepSeek V4 admite diferentes modos de esfuerzo de razonamiento en lugar de imponer un único comportamiento para cada tarea.
Esa es una decisión importante sobre el producto.
Para las solicitudes rutinarias, los usuarios pueden priorizar la velocidad. Para tareas complejas de planificación, codificación o investigación, pueden dedicar más esfuerzo al razonamiento. En la práctica, esto hace que la familia de modelos sea más adaptable a las cargas de trabajo reales que un único estilo de inferencia estática.
6. La afirmación más sólida es la eficiencia en contextos largos.
Muchos lanzamientos de IA hablan de la duración del contexto. Menos aún logran que la ejecución en contextos prolongados parezca operativamente viable.
Aquí es donde V4 puede resultar más interesante.
A Ventana de contexto de 1 millón de tokens ya es una característica principal, pero el detalle más importante es la afirmación de DeepSeek de que V4-Pro solo necesita 27% de las operaciones de punto flotante (FLOP) de inferencia de un solo token y 10% de la caché KV requerido por DeepSeek-V3.2 a esa escala de contexto.
Si esos avances se mantienen en la práctica, podrían ser tan importantes como las puntuaciones de referencia.
Por qué la ventana de contexto de 1 millón de tokens es más importante de lo que parece
Una ventana de contexto de un millón de tokens no es solo una estrategia de marketing.
En términos prácticos, esto significa que los desarrolladores y los equipos pueden procesar cantidades mucho mayores de material fuente en una sola sesión: bases de código extensas, conjuntos de documentación masivos, archivos de investigación, transcripciones de clientes o flujos de trabajo con múltiples archivos que antes requerían estrategias de división en bloques engorrosas.
Esto abre la puerta a varios casos de uso de gran valor:
1. Comprensión de grandes bases de código
Los equipos pueden analizar repositorios más grandes con menos trabajo de segmentación manual, lo que mejora la depuración, la refactorización y los flujos de trabajo de codificación basados en agentes.
2. Investigación y síntesis del conocimiento
En lugar de pasar fragmentos a un modelo y perder el contexto global, los usuarios pueden trabajar con colecciones de origen mucho más grandes de una sola vez.
3. Mejores agentes de IA
Los sistemas de agentes funcionan mejor cuando pueden mantener más memoria en contexto. Para la planificación, el uso de herramientas y la ejecución de tareas de varios pasos, la eficiencia del contexto es casi tan importante como la calidad del razonamiento en sí.
4. Flujos de trabajo de documentos empresariales
Los contratos extensos, los documentos de cumplimiento, los archivos de soporte y las wikis internas se vuelven más manejables dentro de un mismo ciclo de razonamiento.
Dicho esto, la longitud del contexto por sí sola no no Garantizan la calidad. Muchos modelos anuncian ventanas de larga duración, pero su rendimiento disminuye cuando la calidad de recuperación, la concentración en la memoria o la latencia se convierten en un problema.
Por eso, las afirmaciones de DeepSeek sobre su eficiencia son posiblemente más importantes que la cifra de 1 millón en sí misma.
Por qué este lanzamiento se siente más importante que una caída normal de los índices de referencia.
DeepSeek no está posicionando a V4 simplemente como un modelo de contexto extenso.
También está haciendo un gran esfuerzo en razonamiento, codificación, y desempeño de agente.
El comunicado destaca DeepSeek-V4-Pro-Max lo considera el modo de razonamiento más potente de la gama y lo presenta como uno de los mejores modelos de código abierto disponibles actualmente.
En las tablas comparativas publicadas, V4-Pro-Max muestra resultados especialmente sólidos en áreas como:
- LiveCodeBench
- Rendimiento de codificación al estilo Codeforces
- Diamante GPQA
- BrowseComp
- Puntos de referencia de ingeniería de software al estilo SWE
- Pruebas de contexto extenso como MRCR 1M y CorpusQA 1M
La clasificación exacta seguirá cambiando a medida que los laboratorios actualicen sus modelos cada pocas semanas. Pero la señal estratégica ya es clara:
Los modelos de código abierto están adquiriendo cada vez más credibilidad para flujos de trabajo técnicos complejos, y no solo para casos de uso de chat sencillos.
Esa es la verdadera razón por la que este lanzamiento es importante.
La parte más interesante: los modos de razonamiento
DeepSeek V4 admite tres modos de esfuerzo de razonamiento:
- No pensar para respuestas rápidas y ligeras
- Piensa en grande para un análisis más lento y deliberado
- Piensa en Max para un esfuerzo de razonamiento máximo
Esto es importante porque refleja hacia dónde se dirige el mercado de los modelos.
El futuro no es solo “un modelo, un comportamiento”. Se trata cada vez más de inferencia adaptativa: rápido cuando necesitas velocidad, más profundo cuando necesitas precisión.
Para los equipos de producto, esto crea un mejor equilibrio entre:
- estado latente
- costo
- profundidad de razonamiento
- experiencia de usuario
En otras palabras, DeepSeek no solo está lanzando un modelo. Está lanzando un patrón de uso Eso coincide con la forma en que están evolucionando los productos de IA reales.
Qué significa esto para la IA de código abierto
DeepSeek V4 refuerza tres tendencias más amplias.
1. El código abierto es cada vez más difícil de ignorar.
La brecha entre los principales modelos abiertos y cerrados sigue existiendo, pero se está reduciendo de forma visible. Cada lanzamiento importante obliga ahora a los equipos de producto a reevaluar si realmente necesitan un modelo cerrado para cada flujo de trabajo.
2. La eficiencia se está convirtiendo en un campo de batalla de primer orden.
El modelo con la puntuación más alta no es automáticamente el más útil. En implementaciones reales, la eficiencia de la memoria, el rendimiento y el coste de inferencia determinan la viabilidad del producto.
3. Los flujos de trabajo de los agentes están elevando el nivel.
A medida que más empresas desarrollan agentes de IA, los modelos más valiosos son aquellos que pueden manejar contextos extensos, razonamiento en múltiples pasos y ejecución orientada a herramientas al mismo tiempo.
DeepSeek V4 apunta claramente a esa intersección.
Algunas advertencias antes de que la euforia se descontrole.
Esto es un Versión preliminar, Por lo tanto, los equipos deben ser realistas.
Hay algunas cosas que vale la pena ver:
- Latencia en condiciones reales de cargas de contexto prolongado e intensas.
- Consistencia del rendimiento en diferentes estilos de indicaciones
- Fiabilidad del uso de la herramienta fuera de los parámetros de referencia.
- Complejidad de implementación para equipos que desean ejecutarlo localmente.
- Si las mejoras de referencia se traducen en mejores resultados de producción.
DeepSeek también señala que la implementación local requiere su propio flujo de trabajo de codificación e inferencia, en lugar de una plantilla simple lista para usar. Esto no es un inconveniente grave, pero sí significa que la adopción puede ser más sencilla para equipos con experiencia técnica que para usuarios ocasionales.
Toma final
DeepSeek V4 no solo importa por sus especificaciones, sino porque demuestra que DeepSeek puede captar la atención mundial a gran escala.
Por eso la industria vuelve a estar atenta.
En el aspecto técnico, el modelo avanza con una ventana de contexto de 1 millón de tokens, una mayor eficiencia en contextos largos, un rendimiento mejorado en codificación y razonamiento, y una clara tendencia hacia flujos de trabajo de estilo agente.
En el ámbito comercial, llega con gran impulso. DeepSeek ya no parte de cero. Cuenta con reconocimiento de marca global gracias a su anterior éxito, y V4 se lanza a un mercado que busca activamente el próximo salto creíble en el modelo abierto.
Si trabajas con inteligencia artificial, esto no es solo otro lanzamiento de referencia. Es una señal de que los modelos abiertos son cada vez más competitivos, más prácticos y están más preparados para su uso en producción real.
Puede que DeepSeek V4 no ponga fin al debate entre sistemas cerrados y abiertos, pero sin duda eleva el nivel de lo que los equipos pueden esperar de la IA de código abierto en 2026.
Cómo probar DeepSeek V4
Si quieres explorarlo por tu cuenta, hay varias maneras de empezar:
- Ejecutar localmente (control total)
Descarga e implementa a través de Hugging Face:
👉 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro - Pruébalo al instante (sin configuración)
Utilice la interfaz de chat oficial:
👉 https://chat.deepseek.com/ - Integración mediante API (desarrollo con ella)
Acceda a DeepSeek V4 a través de una puerta de enlace API unificada:
👉 https://www.imarouter.com Puedes integrarlo fácilmente en tus flujos de trabajo o herramientas de agente existentes, como OpenClaw, Código Claude, y otros sistemas de automatización.
Fuentes
- Página oficial del modelo: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- TechCrunch: DeepSeek desbanca a ChatGPT como la aplicación más popular de la App Store.
- TechCrunch: DeepSeek alcanza el número 1 en la Play Store de EE. UU.
- CNBC: La IA DeepSeek de China destrona a ChatGPT en la App Store: esto es lo que debes saber.