DeepSeek volta a ser o centro das atenções.
Desta vez, a história é maior do que um simples cartão de modelo.
Com DeepSeek-V4-Pro e DeepSeek-V4-Flash, A DeepSeek não está apenas lançando mais uma família de modelos open-weight. Ela está tentando transformar três ideias em um único lançamento simultâneo:
- um modelo de código aberto emblemático que pode se aproximar mais de sistemas fechados de vanguarda.
- Uma variante mais barata e rápida, mais fácil de implementar em larga escala.
- e Contexto de 1 milhão de tokens Posicionado menos como um recurso de luxo e mais como um padrão prático para cargas de trabalho exigentes.
E isso é importante, porque esta não é a primeira vez que a empresa atrai a atenção global para a inteligência artificial.
Quando o ciclo de modelos anterior do DeepSeek se popularizou em janeiro de 2025, ele se tornou muito mais do que apenas mais um lançamento de código aberto. O TechCrunch relatou que o DeepSeek subiu para Número 1 na App Store dos EUA em 26 de janeiro., depois de saltar de Nº 31 apenas alguns dias antes, e alcançou 2,6 milhões de downloads combinados na App Store e no Google Play. Na manhã de segunda-feira. Um dia depois, o TechCrunch também noticiou que o aplicativo Android da DeepSeek havia atingido Número 1 na Play Store dos EUA, com estimativas da AppFigures Mais de 1,2 milhão de downloads na Play Store e mais de 1,9 milhão de downloads na App Store. em todo o mundo desde o lançamento.
Essa história importa quando se analisa... DeepSeek V4.
O motivo pelo qual as pessoas estão prestando atenção novamente não é apenas porque o V4 tem um janela de contexto de 1 milhão de tokens. Isso porque a DeepSeek já provou que consegue sair da bolha da IA e se tornar um assunto de grande repercussão global.
Esta versão demonstra a rapidez com que a IA de código aberto está reduzindo a diferença em relação aos modelos fechados de ponta — especialmente em codificação, raciocínio e fluxos de trabalho no estilo de agentes. Para equipes que desenvolvem com IA, isso importa mais do que qualquer expectativa exagerada.
Por que o mundo está assistindo novamente?
Existem três razões pelas quais este lançamento está recebendo atenção imediata.
1. A DeepSeek já possui um histórico de sucesso.
DeepSeek deixou de ser um laboratório obscuro. Seu ciclo de lançamentos anterior atraiu a atenção de diversos veículos de comunicação, como... TechCrunch, CNBC, Forbes, Fortune, The Verge e Business Insider — não apenas mídias nativas de IA.
Isso muda a forma como o lançamento de um novo modelo é interpretado. Quando uma marca de IA que já se tornou viral lança outra versão importante, as pessoas não a interpretam como uma "notícia interessante". Elas a interpretam como uma possível segunda onda de sucesso.
2. A versão atual já apresenta sinais iniciais de tração.
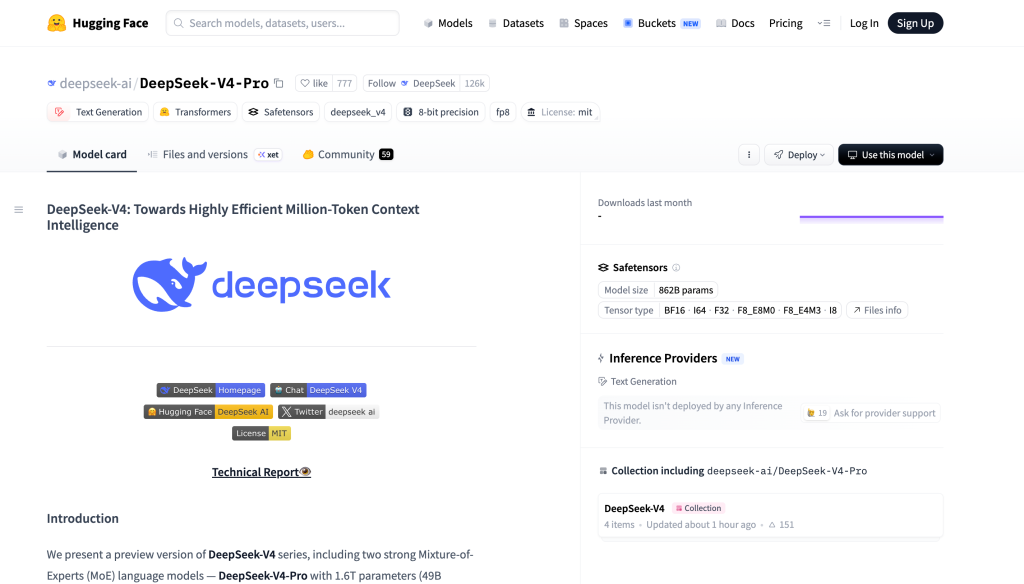
No lançamento, o oficial DeepSeek-V4-Pro A página da Hugging Face apresentou forte engajamento imediato, incluindo uma grande base de seguidores para a DeepSeek e centenas de curtidas na página da modelo nas primeiras horas após o lançamento.
Igualmente importante, uma verificação de pesquisa logo após o lançamento revelou algo interessante: já havia novas explicações, páginas de destino e resumos de benchmarks da versão 4 aparecendo nos resultados de busca — mas essencialmente Não foram encontrados resultados para "análise do DeepSeek V4".“
Isso significa que a atenção está chegando mais rápido do que a interpretação de alta qualidade.
3. A narrativa é maior do que um único modelo.
O DeepSeek V4 chega a um mercado já preparado para a narrativa de que "o código aberto está se recuperando". O novo lançamento se encaixa perfeitamente nessa narrativa mais ampla: raciocínio aprimorado, contexto mais extenso, maior relevância para os agentes e alegações de eficiência mais robustas.
É por isso que isso parece maior do que um lançamento normal de cards de modelos.
Dois modelos, uma estratégia
De acordo com o comunicado oficial da Hugging Face, a série DeepSeek V4 inclui dois modelos Mixture-of-Experts:
- DeepSeek-V4-Pro: 1,6T parâmetros totais, 49B ativados
- DeepSeek-V4-Flash: 284 bilhões de parâmetros totais, 13 bilhões ativados
Ambos os modelos suportam até 1 milhão de tokens de contexto.
Isso é importante porque o DeepSeek não está mais contando uma história baseada em um único modelo.
A leitura mais interessante é que está construindo um estratégia de produto de duas camadas:
- Pró é o carro-chefe, projetado para competir pela atenção em raciocínio, codificação, trabalho de contexto extenso e execução no estilo de agentes.
- Clarão é a camada de valor, projetada para ser menor, mais rápida e muito mais barata para uma implantação mais ampla.
Essa divisão faz com que o lançamento pareça mais maduro do que um lançamento típico focado em benchmarks. Ela oferece aos desenvolvedores e equipes uma escolha realista entre "melhor desempenho" e "melhor eficiência", em vez de forçar ambos os objetivos em um único modelo.
A DeepSeek também afirma que a versão 4 introduz diversas melhorias arquitetônicas projetadas para tornar a inferência de contexto longo mais prática, e não apenas teoricamente possível.
Isso inclui:
- Arquitetura de Atenção Híbrida, combinando Atenção Esparsa Comprimida (CSA) e Atenção Altamente Comprimida (HCA)
- Hiperconexões com Restrição de Variedade (mHC) para melhorar a propagação do sinal entre as camadas
- Otimizador de múons para um treino mais rápido e estável
Segundo os próprios números da DeepSeek, O DeepSeek-V4-Pro utiliza apenas 27% dos FLOPs de inferência de token único e 10% do cache KV exigido pelo DeepSeek-V3.2 em uma configuração de 1 milhão de tokens..
Esse é o tipo de melhoria que desperta o interesse das equipes de infraestrutura.
Há também uma história prática por trás do lançamento do produto. A documentação oficial da API do DeepSeek mostra que ambos deepseek-v4-flash e deepseek-v4-pro estão disponíveis por meio de endpoints compatíveis com OpenAI e Antrópico formatos. Ambos suportam chamadas de ferramentas, saída JSON e um comprimento máximo de saída de 384 mil tokens. Para os desenvolvedores, isso é importante porque facilita a integração da versão 4 em aplicativos e conjuntos de agentes existentes sem a necessidade de reescrevê-los completamente.
Igualmente importante, a DeepSeek já vinculou a V4 a um caminho de migração. Os nomes dos modelos mais antigos bate-papo profundo e deepseek-reasoner estão programados para serem descontinuados em 2026/07/24, com mapeamento de compatibilidade para os modos de não-pensamento e de pensamento de deepseek-v4-flash.
Então, quão bom é o DeepSeek V4 na realidade?
Se deixarmos de lado a propaganda e analisarmos o material oficial, a resposta é: O DeepSeek V4 parece realmente robusto — especialmente para trabalhos de contexto extenso, programação e fluxos de trabalho que exigem muito raciocínio — mas ainda deve ser considerado uma prévia muito promissora, e não um vencedor definitivo.
Essa é a forma mais justa de apresentar uma avaliação.
1. O DeepSeek V4-Pro parece ser um carro-chefe de código aberto de verdade.
Em teoria, DeepSeek-V4-Pro-Max É evidente que o objetivo é competir com modelos de vanguarda, e não apenas com outros lançamentos de código aberto.
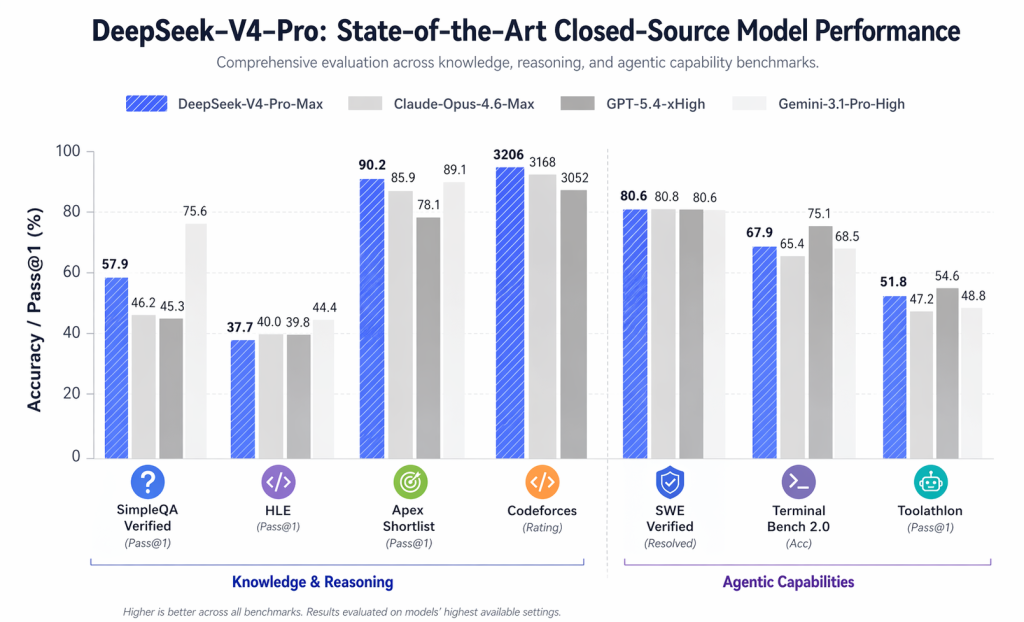
Na tabela comparativa oficial, são apresentados números notáveis como:
- LiveCodeBench: 93,5
- Classificação no Codeforces: 3206
- GPQA Diamante: 90,1
- Verificado pela SWE: 80,6
- MRCR 1M: 83,5
A principal conclusão não é que o DeepSeek V4 supera todos os modelos fechados em todos os aspectos. Não supera. A conclusão mais plausível é que agora ele merece estar no mesmo nível de comparação para diversas tarefas técnicas avançadas.
2. Flash pode ser a história surpreendente.
Muita atenção será dada à variante Pro, mas DeepSeek-V4-Flash pode acabar sendo tão importante comercialmente quanto.
De acordo com a página de preços da API da DeepSeek, o V4-Flash custa:
- $0.14 / 1M tokens de entrada (falha de cache)
- $0.028 / 1M tokens de entrada (acerto de cache)
- $0.28 / 1M tokens de saída
Em comparação, DeepSeek-V4-Pro tem o seguinte preço:
- $1.74 / 1M tokens de entrada (falha de cache)
- $0.145 / 1M tokens de entrada (acerto de cache)
- $3.48 / 1M tokens de saída
Isso cria uma narrativa de produto mais interessante do que "vencem o mercado com modelos maiores". O Flash oferece ao DeepSeek uma camada de valor realista para casos de uso de alto volume, enquanto o Pro mantém o posicionamento de produto principal.
3. A DeepSeek quer vencer a conversa com o agente, não apenas a conversa com o chatbot.
Um dos sinais mais claros na versão V4 é o que a DeepSeek opta por enfatizar.
As tabelas de avaliação oficiais não se limitam a critérios de conhecimento e raciocínio. Elas também destacam tarefas orientadas à ação e ao uso de ferramentas como:
- Bancada Terminal 2.0
- Verificado pela SWE
- SWE Pro
- BrowseComp
- Atlas MCPA
- Toolathlon
Isso é importante porque sugere que a DeepSeek quer que a versão 4 seja avaliada como uma família de modelos pronta para agenciamento, não apenas como um chatbot ou assistente de programação.
Para equipes que desenvolvem produtos de IA, essa ambição é mais relevante do que simplesmente disputar posições em rankings.
4. Flash pode ser a história surpreendente.
Muita atenção será dada à variante Pro, mas DeepSeek-V4-Flash pode acabar sendo tão importante comercialmente quanto.
De acordo com a página de preços da API da DeepSeek, o V4-Flash custa:
- $0.14 / 1M tokens de entrada (falha de cache)
- $0.028 / 1M tokens de entrada (acerto de cache)
- $0.28 / 1M tokens de saída
Em comparação, DeepSeek-V4-Pro tem o seguinte preço:
- $1.74 / 1M tokens de entrada (falha de cache)
- $0.145 / 1M tokens de entrada (acerto de cache)
- $3.48 / 1M tokens de saída
Isso cria uma narrativa de produto mais interessante do que "vencem o mercado com modelos maiores". O Flash oferece ao DeepSeek uma camada de valor realista para casos de uso de alto volume, enquanto o Pro mantém o posicionamento de produto principal.
5. Os modos de raciocínio representam uma verdadeira vantagem em termos de usabilidade.
O DeepSeek V4 suporta diferentes modos de esforço de raciocínio, em vez de forçar um único comportamento para cada tarefa.
Essa é uma decisão de produto significativa.
Para solicitações rotineiras, os usuários podem priorizar a velocidade. Para tarefas complexas de planejamento, codificação ou pesquisa, podem alocar mais esforço de raciocínio. Na prática, isso torna a família de modelos mais adaptável a cargas de trabalho reais do que um único estilo de inferência estática.
6. A alegação mais forte é a eficiência em contextos de longo prazo.
Muitos lançamentos de IA falam sobre o comprimento do contexto. Poucos, porém, conseguem fazer com que a execução em contextos longos pareça operacionalmente plausível.
É aqui que a versão 4 pode ser mais interessante.
A Janela de contexto de 1 milhão de tokens já é um recurso de destaque, mas o detalhe mais importante é a afirmação da DeepSeek de que o V4-Pro precisa apenas de 27% dos FLOPs de inferência de token único e 10% do cache KV exigido pelo DeepSeek-V3.2 nessa escala de contexto.
Se esses ganhos se confirmarem na prática, isso poderá ser tão importante quanto as pontuações de referência.
Por que a janela de contexto de 1 milhão de tokens é mais importante do que parece
Uma janela de contexto com um milhão de tokens não é apenas uma estratégia de marketing.
Na prática, isso significa que desenvolvedores e equipes podem inserir quantidades muito maiores de material de origem em uma única sessão — bases de código extensas, conjuntos de documentação massivos, arquivos de pesquisa, transcrições de clientes ou fluxos de trabalho com vários arquivos que antes exigiam estratégias de fragmentação complicadas.
Isso abre diversas possibilidades de uso de alto valor:
1. Compreensão de bases de código extensas
As equipes podem analisar repositórios maiores com menos segmentação manual, o que melhora a depuração, a refatoração e os fluxos de trabalho de codificação baseados em agentes.
2. Pesquisa e síntese de conhecimento
Em vez de passar fragmentos para um modelo e perder o contexto global, os usuários podem trabalhar com coleções de código-fonte muito maiores de uma só vez.
3. Agentes de IA melhores
Sistemas de agentes têm melhor desempenho quando conseguem manter mais memória em contexto. Para planejamento, uso de ferramentas e execução de tarefas com várias etapas, a eficiência do contexto importa quase tanto quanto a qualidade do raciocínio em si.
4. Fluxos de trabalho de documentos empresariais
Contratos extensos, documentos de conformidade, arquivos de suporte e wikis internas tornam-se mais gerenciáveis dentro de um único ciclo de raciocínio.
Dito isso, o comprimento do contexto por si só não faz nada não Garantir a qualidade. Muitos modelos anunciam janelas de tempo longas, mas apresentam desempenho inferior quando a qualidade de recuperação, o foco da memória ou a latência se tornam um problema.
É por isso que as alegações de eficiência da DeepSeek são, sem dúvida, mais importantes do que o próprio número de 1 milhão.
Por que este lançamento parece maior do que um lançamento de referência normal?
A DeepSeek não está posicionando o V4 apenas como um modelo de contexto longo.
Também está investindo seriamente em raciocínio, codificação, e desempenho agente.
O comunicado destaca DeepSeek-V4-Pro-Max como o modo de raciocínio mais robusto da linha de produtos, e o classifica como um dos melhores modelos de código aberto disponíveis atualmente.
Nas tabelas comparativas publicadas, o V4-Pro-Max apresenta resultados particularmente expressivos em áreas como:
- LiveCodeBench
- desempenho de codificação no estilo Codeforces
- Diamante GPQA
- BrowseComp
- Benchmarks de engenharia de software no estilo SWE
- Testes de contexto longo, como MRCR 1M e CorpusQA 1M.
A classificação exata continuará mudando à medida que os laboratórios atualizam seus modelos a cada poucas semanas. Mas o sinal estratégico já está claro:
Os modelos de código aberto estão se tornando cada vez mais viáveis para fluxos de trabalho técnicos complexos, e não apenas para casos de uso de bate-papo simples.
Essa é a verdadeira razão pela qual este lançamento é importante.
A parte mais interessante: Modos de raciocínio
O DeepSeek V4 suporta três modos de esforço de raciocínio:
- Não pensar para respostas rápidas e leves
- Pense Alto para uma análise mais lenta e ponderada.
- Pense Max para um esforço máximo de raciocínio
Isso é importante porque reflete a direção para onde o mercado de modelos está caminhando.
O futuro não se resume a “um modelo, um comportamento”. Trata-se cada vez mais de... inferência adaptativaRápido quando você precisa de velocidade, mais profundo quando você precisa de precisão.
Para as equipes de produto, isso cria um melhor equilíbrio entre:
- latência
- custo
- profundidade de raciocínio
- experiência do usuário
Em outras palavras, a DeepSeek não está apenas lançando um modelo. Ela está lançando um padrão de uso Isso corresponde à forma como os produtos reais de IA estão evoluindo.
O que isso significa para a IA de código aberto?
O DeepSeek V4 reforça três tendências mais amplas.
1. O código aberto está se tornando cada vez mais difícil de ignorar.
A diferença entre os principais modelos abertos e fechados ainda é real, mas está diminuindo de forma visível. Cada grande lançamento agora força as equipes de produto a reavaliarem se realmente precisam de um modelo fechado para cada fluxo de trabalho.
2. A eficiência está se tornando um campo de batalha de primeira classe.
O modelo com a pontuação mais alta não é automaticamente o modelo mais útil. Para implementações reais, a eficiência da memória, a taxa de transferência e o custo da inferência determinam a viabilidade do produto.
3. Os fluxos de trabalho dos agentes estão elevando o padrão.
À medida que mais empresas desenvolvem agentes de IA, os modelos mais valiosos são aqueles que conseguem lidar simultaneamente com contextos extensos, raciocínio em várias etapas e execução orientada a ferramentas.
O DeepSeek V4 está claramente mirando nessa interseção.
Algumas ressalvas antes que a empolgação saia do controle.
Isto é um versão prévia, Portanto, as equipes devem manter o realismo.
Algumas coisas valem a pena assistir:
- Latência no mundo real sob cargas pesadas de contexto longo
- Consistência de desempenho em diferentes estilos de estímulo.
- Confiabilidade do uso da ferramenta fora dos ambientes de teste
- Complexidade de implantação para equipes que desejam executá-lo localmente.
- Se os ganhos de referência se traduzem em resultados de produção mais robustos.
A DeepSeek também observa que a implantação local requer seu próprio fluxo de trabalho de codificação e inferência, em vez de um modelo simples e pronto para uso. Isso não é um grande problema, mas significa que a adoção pode ser mais fácil para equipes com experiência técnica do que para usuários casuais.
Tomada final
O DeepSeek V4 é importante não apenas por suas especificações, mas porque comprova que o DeepSeek consegue capturar a atenção global em grande escala.
É por isso que a indústria está observando novamente.
Do ponto de vista técnico, o modelo avança com uma janela de contexto de 1 milhão de tokens, maior eficiência em contextos longos, melhor desempenho de codificação e raciocínio e uma clara tendência em direção a fluxos de trabalho no estilo de agentes.
Do ponto de vista do mercado, chega com grande impulso. A DeepSeek já não está a começar do zero. Já possui reconhecimento global de marca graças ao seu sucesso anterior, e a V4 está a ser lançada num mercado que procura ativamente o próximo salto significativo para modelos abertos.
Se você está desenvolvendo com IA, este não é apenas mais um lançamento de benchmark. É um sinal de que os modelos abertos estão se tornando mais competitivos, mais práticos e cada vez mais prontos para uso em produção real.
O DeepSeek V4 pode não acabar com o debate entre sistemas fechados e abertos, mas certamente eleva o padrão do que as equipes podem esperar da IA de código aberto em 2026.
Como experimentar o DeepSeek V4
Se você quiser explorar por conta própria, existem algumas maneiras de começar:
- Executar localmente (controle total)
Faça o download e a implantação via Hugging Face:
👉 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro - Experimente agora mesmo (sem configuração)
Utilize a interface de chat oficial:
👉 https://chat.deepseek.com/ - Integre via API (desenvolva com ela)
Acesse o DeepSeek V4 por meio de um gateway de API unificado:
👉 https://www.imarouter.com Você pode integrá-lo facilmente aos seus fluxos de trabalho ou ferramentas de agente existentes, como por exemplo... OpenClaw, Código Claude, e outros sistemas de automação.
Fontes
- Página oficial do modelo: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- TechCrunch: DeepSeek desbanca o ChatGPT como o aplicativo mais baixado da App Store
- TechCrunch: DeepSeek alcança o 1º lugar na Play Store dos EUA
- CNBC: A DeepSeek, empresa chinesa de inteligência artificial, destrona o ChatGPT na App Store: veja o que você precisa saber.