DeepSeek est de retour sur le devant de la scène.
Cette fois, l'enjeu dépasse le simple cadre d'une carte de visite.
Avec DeepSeek-V4-Pro et DeepSeek-V4-Flash, DeepSeek ne se contente pas de lancer une nouvelle gamme de modèles à poids libre. L'entreprise tente de fusionner trois idées en un seul lancement :
- un modèle open source phare qui peut se rapprocher des systèmes fermés de pointe
- une variante moins chère et plus rapide, plus facile à déployer à grande échelle
- et Contexte de jeton 1M positionnée moins comme une fonctionnalité de luxe et plus comme une valeur par défaut pratique pour les charges de travail importantes.
Et c'est important, car ce n'est pas la première fois que l'entreprise attire l'attention du monde entier sur l'IA.
Lorsque le premier cycle de développement de DeepSeek a percé en janvier 2025, il est devenu bien plus qu'un simple lancement open source. TechCrunch a rapporté que DeepSeek avait atteint… Numéro 1 sur l'App Store américain le 26 janvier, après avoir sauté de Le numéro 31, quelques jours plus tôt., et a atteint 2,6 millions de téléchargements cumulés sur l'App Store et Google Play Lundi matin. Le lendemain, TechCrunch a également rapporté que l'application Android de DeepSeek avait rencontré un certain succès. Numéro 1 sur le Play Store américain, avec AppFigures estimant Plus de 1,2 million de téléchargements sur le Play Store et plus de 1,9 million de téléchargements sur l'App Store. mondial depuis son lancement.
Cette histoire est importante lorsqu'on examine DeepSeek V4.
Si l'attention se porte à nouveau sur V4, ce n'est pas seulement parce que V4 possède un Fenêtre de contexte de 1 million de jetons. C’est parce que DeepSeek a déjà prouvé qu’elle pouvait sortir de la bulle de l’IA et devenir un phénomène mondial.
Cette publication démontre la rapidité avec laquelle l'IA open source rattrape les modèles fermés de pointe, notamment en matière de programmation, de raisonnement et de flux de travail de type agent. Pour les équipes qui développent avec l'IA, cela compte bien plus que le simple effet de mode.
Pourquoi le monde regarde à nouveau
Ce lancement attire immédiatement l'attention pour trois raisons.
1. DeepSeek a déjà un historique de percées
DeepSeek n'est plus un laboratoire confidentiel. Son précédent cycle de publication a fait l'objet d'articles dans des médias tels que TechCrunch, CNBC, Forbes, Fortune, The Verge et Business Insider — et pas seulement les médias natifs de l'IA.
Cela change la façon dont le lancement d'un nouveau modèle est interprété. Lorsqu'une marque d'IA ayant déjà connu un succès viral lance une nouvelle version majeure, les gens ne le perçoivent pas comme une “ information intéressante ”, mais plutôt comme le signe d'une possible deuxième vague de croissance.
2. La version actuelle montre déjà des signes encourageants.
Au lancement, l'officiel DeepSeek-V4-Pro La page sur Hugging Face a enregistré un fort engagement immédiat, avec notamment une large base d'abonnés pour DeepSeek et des centaines de mentions « J'aime » sur la page du modèle dans les premières heures suivant sa sortie.
Tout aussi important, une vérification de recherche effectuée juste après le lancement a révélé un fait intéressant : des explications, des pages de destination et des résumés de performances de la version 4 apparaissaient déjà dans les résultats de recherche, mais essentiellement… Aucun résultat trouvé pour “ Avis sur DeepSeek V4 ”.”
Cela signifie que l'attention arrive plus vite que l'interprétation de qualité.
3. Le récit dépasse le cadre d'un seul modèle.
DeepSeek V4 arrive sur un marché déjà mûr pour le retour en force des solutions open source. Cette nouvelle version s'inscrit pleinement dans cette tendance : un raisonnement amélioré, un contexte plus étendu, une meilleure pertinence des agents et des gains d'efficacité accrus.
C'est pourquoi cela paraît plus important qu'une simple sortie de carte graphique.
Deux modèles, une stratégie
Selon le communiqué officiel de Hugging Face, la série DeepSeek V4 comprend deux modèles Mixture-of-Experts :
- DeepSeek-V4-Pro: 1,6T paramètres totaux, 49B activés
- DeepSeek-V4-Flash284B de paramètres au total, dont 13B activés
Les deux modèles sont compatibles jusqu'à 1 million de jetons de contexte.
C’est important car DeepSeek ne se contente plus de raconter l’histoire d’un seul modèle.
Le plus intéressant, c'est que cela est en train de construire un stratégie produit à deux niveaux:
- Pro est le produit phare, conçu pour rivaliser en matière de raisonnement, de codage, de traitement de données à long contexte et d'exécution de type agent.
- Éclair est la couche de valeur, conçue pour être plus petite, plus rapide et beaucoup moins chère pour un déploiement plus large
Cette distinction confère au lancement une apparence plus mature qu'une version classique axée sur les performances de référence. Elle offre aux développeurs et aux équipes un choix réaliste entre “ performances optimales ” et “ efficacité optimale ”, au lieu d'imposer les deux objectifs dans un seul modèle.
DeepSeek indique également que la version V4 introduit plusieurs améliorations architecturales conçues pour rendre l'inférence à long contexte plus pratique, et non plus seulement théoriquement possible.
Cela comprend :
- Architecture d'attention hybride, combinant l'attention clairsemée compressée (CSA) et l'attention fortement compressée (HCA)
- Hyperconnexions à contrainte de variété (mHC) pour améliorer la propagation du signal à travers les couches
- Optimiseur de muons pour un entraînement plus rapide et plus stable
D'après les chiffres de DeepSeek, DeepSeek-V4-Pro utilise seulement 271 TP3T des FLOP d'inférence à jeton unique et 101 TP3T du cache KV requis par DeepSeek-V3.2 dans une configuration à 1 million de jetons..
Voilà le genre d'amélioration qui intéresse les équipes d'infrastructure.
Il y a aussi une histoire de produit concrète derrière ce lancement. La documentation officielle de l'API de DeepSeek montre que les deux deepseek-v4-flash et deepseek-v4-pro sont disponibles via des points de terminaison compatibles avec OpenAI et Anthropique Les deux formats prennent en charge les appels d'outils, la sortie JSON et une longueur de sortie maximale de 384 000 jetons. Pour les développeurs, c'est important car cela facilite l'intégration de la version V4 dans les applications et les piles d'agents existantes sans avoir à la réécrire entièrement.
Tout aussi important, DeepSeek a déjà associé la V4 à un processus de migration. Les noms des anciens modèles chat deepseek et deepseek-reasoner leur dépréciation est prévue pour le 2026/07/24, avec une correspondance de compatibilité les associant aux modes non-pensants et pensants de deepseek-v4-flash.
Alors, DeepSeek V4 est-il vraiment si performant ?
Si l'on fait abstraction du battage médiatique et que l'on se penche sur les documents officiels, la réponse est : DeepSeek V4 semble vraiment performant, notamment pour les tâches à contexte long, le codage et les flux de travail nécessitant un raisonnement poussé, mais il doit encore être considéré comme un aperçu très prometteur plutôt que comme un vainqueur incontestable.
C'est la formulation la plus juste pour une évaluation.
1. Le DeepSeek V4-Pro ressemble à un fleuron open source sérieux
Sur le papier, DeepSeek-V4-Pro-Max Il est clair qu'il vise à concurrencer les modèles Frontier, et pas seulement d'autres distributions open source.
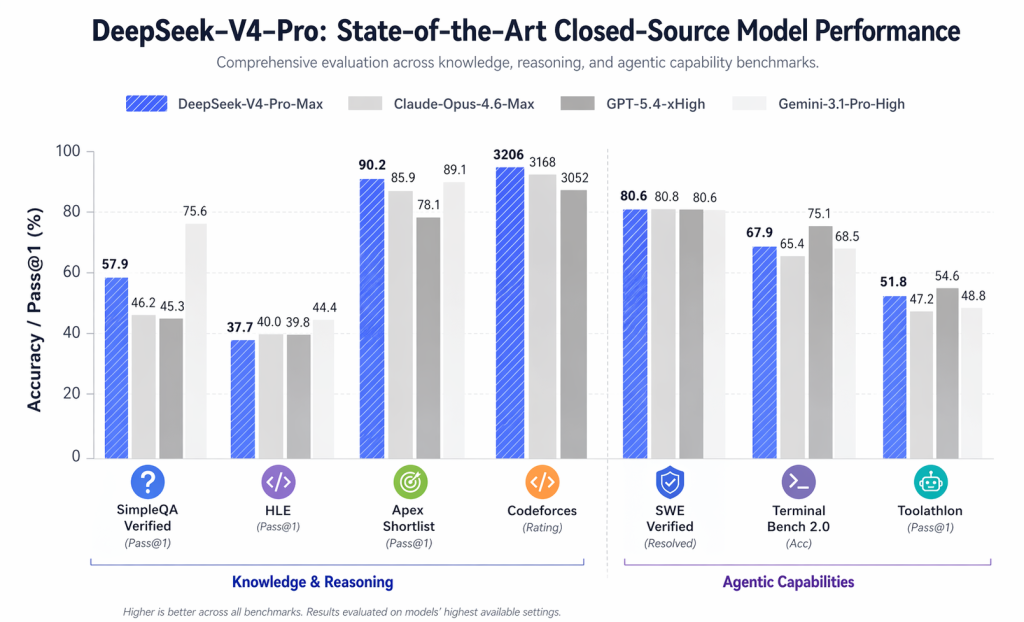
Le tableau comparatif officiel présente des chiffres notables tels que :
- LiveCodeBench : 93,5
- Évaluation Codeforces : 3206
- Diamant GPQA : 90,1
- Vérifié par SWE : 80,6
- MRCR 1M : 83,5
L'enseignement principal n'est pas que DeepSeek V4 surpasse systématiquement tous les modèles propriétaires. Ce n'est pas le cas. La conclusion la plus plausible est qu'il a désormais toute sa place parmi les solutions sérieuses pour de nombreuses tâches techniques avancées.
2. Flash pourrait bien être la révélation de l'année.
L'attention se portera principalement sur la version Pro, mais DeepSeek-V4-Flash pourrait s'avérer tout aussi important sur le plan commercial.
D'après la page de tarification de l'API de DeepSeek, le prix de V4-Flash est le suivant :
- $0.14 / 1M jetons d'entrée (échec de cache)
- $0.028 / 1M jetons d'entrée (cache réussi)
- $0.28 / 1M de jetons de sortie
En comparaison, DeepSeek-V4-Pro son prix est de :
- $1.74 / 1M jetons d'entrée (échec de cache)
- $0.145 / 1M jetons d'entrée (cache atteint)
- $3.48 / 1M de jetons de sortie
Cela crée un récit produit plus intéressant que la simple victoire du modèle phare. Flash confère à DeepSeek une valeur ajoutée réaliste pour les cas d'utilisation à grand volume, tandis que Pro assure le positionnement haut de gamme.
3. DeepSeek souhaite remporter la conversation avec l'agent, et pas seulement celle avec le chatbot.
L'un des signaux les plus clairs de la version V4 est ce que DeepSeek choisit de mettre en avant.
Les tableaux d'évaluation officiels ne se limitent pas aux critères de connaissances et de raisonnement. Ils mettent également en évidence tâches axées sur l'agentivité et l'utilisation d'outils tel que:
- Banc terminal 2.0
- Vérifié par SWE
- SWE Pro
- BrowseComp
- MCPAtlas
- Toolathlon
C'est important car cela suggère que DeepSeek souhaite que V4 soit jugé comme un famille modèle prête à l'emploi pour les agents, et pas seulement en tant que chatbot ou assistant de programmation.
Pour les équipes qui développent des produits d'IA, c'est une ambition bien plus pertinente que le simple spectacle des classements.
4. Flash pourrait bien être la révélation de l'année.
L'attention se portera principalement sur la version Pro, mais DeepSeek-V4-Flash pourrait s'avérer tout aussi important sur le plan commercial.
D'après la page de tarification de l'API de DeepSeek, le prix de V4-Flash est le suivant :
- $0.14 / 1M jetons d'entrée (échec de cache)
- $0.028 / 1M jetons d'entrée (cache réussi)
- $0.28 / 1M de jetons de sortie
En comparaison, DeepSeek-V4-Pro son prix est de :
- $1.74 / 1M jetons d'entrée (échec de cache)
- $0.145 / 1M jetons d'entrée (cache atteint)
- $3.48 / 1M de jetons de sortie
Cela crée un récit produit plus intéressant que la simple victoire du modèle phare. Flash confère à DeepSeek une valeur ajoutée réaliste pour les cas d'utilisation à grand volume, tandis que Pro assure le positionnement haut de gamme.
5. Les modes de raisonnement constituent un véritable avantage en termes d'utilisabilité.
DeepSeek V4 prend en charge différents modes d'effort de raisonnement au lieu d'imposer un comportement unique pour chaque tâche.
Il s'agit d'une décision produit importante.
Pour les requêtes courantes, les utilisateurs peuvent privilégier la rapidité. Pour les tâches complexes de planification, de programmation ou de recherche, ils peuvent consacrer davantage d'efforts au raisonnement. En pratique, cela rend la famille de modèles plus adaptable aux charges de travail réelles qu'un modèle d'inférence statique unique.
6. L'argument le plus convaincant est l'efficacité à long terme
De nombreux lancements d'IA évoquent la longueur du contexte. Rares sont ceux qui rendent l'exécution sur une longue période opérationnellement crédible.
C'est là que la version V4 pourrait s'avérer la plus intéressante.
A fenêtre de contexte de 1 million de jetons est déjà un atout majeur, mais le détail le plus important est l'affirmation de DeepSeek selon laquelle le V4-Pro n'a besoin que de 27% des FLOP d'inférence à jeton unique et 10% du cache KV requis par DeepSeek-V3.2 à cette échelle de contexte.
Si ces progrès se confirment dans la pratique, cela pourrait être tout aussi important que les scores de référence.
Pourquoi la fenêtre de contexte d'un million de jetons est plus importante qu'il n'y paraît
Une fenêtre de contexte d'un million de jetons n'est pas qu'un simple argument marketing.
Concrètement, cela signifie que les développeurs et les équipes peuvent intégrer des quantités beaucoup plus importantes de données sources dans une seule session : de longs ensembles de code, des ensembles de documentation massifs, des archives de recherche, des transcriptions clients ou des flux de travail multi-fichiers qui nécessitaient auparavant des stratégies de découpage complexes.
Cela ouvre la voie à plusieurs cas d'utilisation à forte valeur ajoutée :
1. Compréhension d'une base de code importante
Les équipes peuvent analyser des référentiels plus volumineux avec moins de découpage manuel, ce qui améliore le débogage, la refactorisation et les flux de travail de codage basés sur des agents.
2. Recherche et synthèse des connaissances
Au lieu de transmettre des fragments à un modèle et de perdre le contexte global, les utilisateurs peuvent travailler en une seule opération avec des collections de sources beaucoup plus importantes.
3. Des agents d'IA plus performants
Les systèmes d'agents sont plus performants lorsqu'ils peuvent conserver davantage de données contextuelles. Pour la planification, l'utilisation d'outils et l'exécution de tâches en plusieurs étapes, l'efficacité du contexte est presque aussi importante que la qualité du raisonnement brut.
4. Flux de travail documentaires d'entreprise
Les contrats longs, les documents de conformité, les archives de support et les wikis internes deviennent plus faciles à gérer au sein d'une même boucle de raisonnement.
Cela dit, la longueur du contexte en elle-même pas La qualité est garantie. De nombreux modèles mettent en avant de longues fenêtres de chargement, mais leurs performances se dégradent lorsque la qualité de récupération, la concentration en mémoire ou la latence deviennent problématiques.
C’est pourquoi les affirmations de DeepSeek concernant son efficacité sont sans doute plus importantes que le chiffre d’un million lui-même.
Pourquoi ce lancement semble plus important qu'une baisse de référence normale
DeepSeek ne positionne pas V4 comme un simple modèle à contexte long.
Elle déploie également des efforts considérables dans raisonnement, codage, et performance de l'agent.
Les points saillants de la sortie DeepSeek-V4-Pro-Max comme le mode de raisonnement le plus performant de la gamme, et le présente comme l'un des meilleurs modèles open source actuellement disponibles.
Dans les tableaux comparatifs publiés, le V4-Pro-Max affiche des résultats particulièrement solides dans des domaines tels que :
- LiveCodeBench
- Performances de codage de type Codeforces
- Diamant GPQA
- BrowseComp
- Points de référence en ingénierie logicielle de type SWE
- Les tests à contexte long tels que MRCR 1M et CorpusQA 1M
Le classement exact continuera d'évoluer au gré des mises à jour régulières des modèles par les laboratoires. Mais le signal stratégique est déjà clair :
Les modèles open source gagnent en crédibilité pour les flux de travail techniques complexes, et non plus seulement pour les cas d'utilisation de messagerie instantanée légère.
Voilà la véritable raison pour laquelle ce lancement est important.
La partie la plus intéressante : les modes de raisonnement
DeepSeek V4 prend en charge trois modes d'effort de raisonnement :
- Non-pensée pour des réponses rapides et légères
- Pensez haut pour une analyse plus lente et plus réfléchie
- Pensez Max pour un effort de raisonnement maximal
C'est important car cela reflète la direction que prend le marché des modèles réduits.
L'avenir ne se résume pas à “ un modèle, un comportement ”. Il s'agit de plus en plus de inférence adaptativeRapide quand vous avez besoin de vitesse, plus précis quand vous avez besoin de précision.
Pour les équipes produit, cela crée un meilleur équilibre entre :
- latence
- coût
- profondeur du raisonnement
- expérience utilisateur
En d'autres termes, DeepSeek ne se contente pas de livrer un modèle. Il livre un modèle d'utilisation Cela correspond à l'évolution des produits d'IA réels.
Quelles sont les conséquences pour l'IA open source ?
DeepSeek V4 renforce trois grandes tendances.
1. Il devient de plus en plus difficile d'ignorer les logiciels libres.
L'écart entre les meilleurs modèles ouverts et fermés demeure réel, mais il se réduit de manière visible. Chaque mise à jour majeure oblige désormais les équipes produit à réévaluer la nécessité réelle d'un modèle fermé pour chaque flux de travail.
2. L'efficacité devient un champ de bataille de premier plan
Le modèle ayant le meilleur score n'est pas forcément le plus utile. En pratique, la viabilité du produit dépend de l'efficacité de la mémoire, du débit et du coût d'inférence.
3. Les flux de travail des agents rehaussent les exigences.
À mesure que de plus en plus d'entreprises développent des agents d'IA, les modèles les plus précieux sont ceux qui peuvent gérer simultanément un contexte long, un raisonnement en plusieurs étapes et une exécution orientée outil.
DeepSeek V4 vise clairement ce point de convergence.
Quelques mises en garde avant que l'engouement ne devienne incontrôlable
Ceci est un version préliminaire, Les équipes doivent donc rester réalistes.
Quelques points méritent d'être surveillés :
- Latence réelle sous des charges importantes et des contextes longs
- Cohérence des performances selon les différents styles d'incitation
- Fiabilité de l'utilisation des outils en dehors des paramètres de référence
- Complexité du déploiement pour les équipes qui souhaitent l'exécuter localement
- La question de savoir si les gains de référence se traduisent par de meilleurs résultats de production
DeepSeek souligne également que le déploiement local nécessite son propre flux de travail d'encodage et d'inférence, et non un modèle prêt à l'emploi. Ce n'est pas un obstacle insurmontable, mais cela signifie que l'adoption sera probablement plus aisée pour les équipes techniquement expérimentées que pour les utilisateurs occasionnels.
Dernière prise
DeepSeek V4 est important non seulement pour ses spécifications techniques, mais aussi parce qu'il prouve que DeepSeek peut capter l'attention du monde entier à grande échelle.
C'est pourquoi l'industrie observe à nouveau.
Sur le plan technique, le modèle progresse avec une fenêtre de contexte de 1 million de jetons, une efficacité accrue pour les contextes longs, des performances de codage et de raisonnement améliorées et une évolution claire vers des flux de travail de type agent.
Sur le marché, la nouvelle version arrive en force. DeepSeek ne part plus de zéro. Forte d'une notoriété mondiale acquise grâce à son précédent succès, la V4 s'impose sur un marché en quête d'une innovation crédible dans le domaine des solutions open-model.
Si vous développez avec l'IA, il ne s'agit pas simplement d'une nouvelle publication de benchmark. C'est le signe que les modèles ouverts deviennent plus compétitifs, plus pratiques et de plus en plus prêts pour une utilisation en production.
DeepSeek V4 ne mettra peut-être pas fin au débat entre solutions fermées et ouvertes. Mais il rehausse assurément le niveau d'exigence que les équipes peuvent attendre de l'IA open source en 2026.
Comment essayer DeepSeek V4
Si vous souhaitez l'explorer vous-même, il existe plusieurs façons de commencer :
- Exécuter en local (contrôle total)
Téléchargez et déployez via Hugging Face :
👉 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro - Essayez instantanément (sans installation)
Utilisez l'interface de chat officielle :
👉 https://chat.deepseek.com/ - Intégrer via API (construire avec)
Accédez à DeepSeek V4 via une passerelle API unifiée :
👉 https://www.imarouter.com Vous pouvez facilement l'intégrer à vos flux de travail ou outils d'agents existants, comme OpenClaw, Code Claude, et d'autres systèmes d'automatisation.
Sources
- Page officielle du modèle : https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- TechCrunch : DeepSeek détrône ChatGPT et devient l'application la plus populaire de l'App Store
- TechCrunch : DeepSeek atteint la première place du Play Store américain
- CNBC : DeepSeek AI, l’application chinoise, détrône ChatGPT sur l’App Store : voici ce qu’il faut savoir