For months, Dreamina Seedance 2.0 was the model to beat in AI video generation. Then, in early April 2026, a pseudonymous newcomer called HappyHorse-1.0 appeared on the Artificial Analysis Video Arena — and beat it. Decisively.
This is a head-to-head breakdown: what each model does, where they differ, and which one to use depending on your workflow.
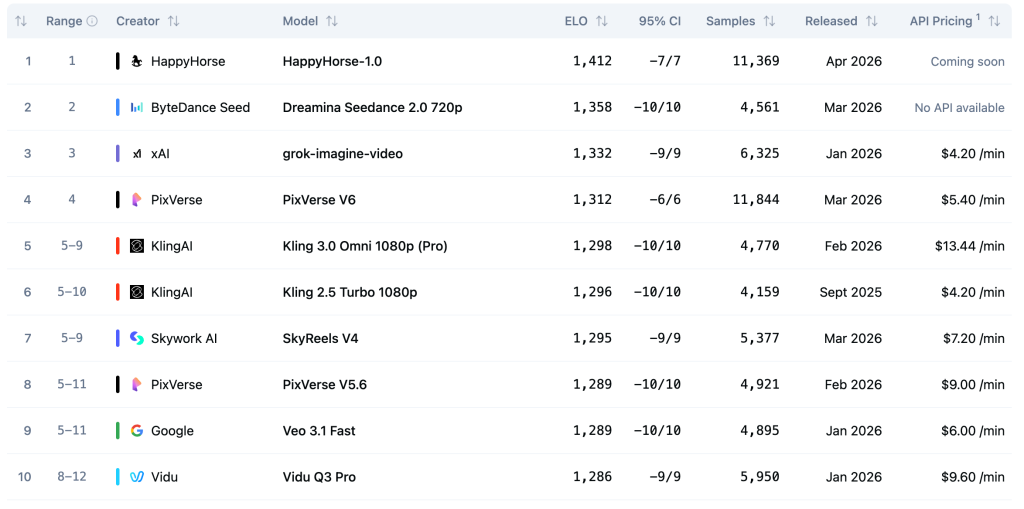
The Leaderboard: Where They Stand
The Artificial Analysis Video Arena uses blind Elo ratings — real users vote without knowing which model produced which output. It’s the closest thing to an objective quality signal in AI video right now.
| Category | HappyHorse-1.0 | Seedance 2.0 | Winner |
|---|---|---|---|
| Text-to-Video (no audio) | 1333 (#1) | 1273 (#2) | 🏆 HappyHorse |
| Image-to-Video (no audio) | 1392 (#1) | 1355 (#2) | 🏆 HappyHorse |
| Text-to-Video (with audio) | 1205 (#2) | 1219 (#1) | 🏆 Seedance 2.0 |
| Image-to-Video (with audio) | 1161 (#2) | 1162 (#1) | 🤝 Tie (1pt gap) |
Bottom line: HappyHorse leads by 60 Elo points in T2V and 37 points in I2V when audio is excluded. When audio is included, Seedance 2.0 edges back — by 14 points in T2V and literally 1 point in I2V.
For pure visual quality and motion realism: HappyHorse-1.0 wins. For synchronized audio-video output: Seedance 2.0 has a narrow lead.
Head-to-Head: Architecture & Capabilities
| Feature | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| Architecture | Single unified Transformer (40 layers) | Diffusion-based (ByteDance) |
| Parameters | ~15B (claimed) | Not disclosed |
| Text-to-Video | ✅ | ✅ |
| Image-to-Video | ✅ (same model) | ✅ |
| Joint audio synthesis | ✅ (1 pass) | ✅ |
| Multilingual audio | 6 languages (ZH/EN/JA/KO/DE/FR) | Limited |
| Open source | Claimed (not yet released) | ❌ Closed |
| Public API | Not yet | Via Dreamina |
| Origin | Unknown (speculated: Alibaba WAN 2.7) | ByteDance / Dreamina |
Visual Quality: What the Votes Are Actually Saying
A 60-point Elo gap in T2V means HappyHorse-1.0 wins approximately 58–59% of direct matchups against Seedance 2.0. In a blind test setting, that’s a clear and consistent preference — not a statistical blip.
Community feedback points to a few specific areas where HappyHorse pulls ahead:
- Motion fluidity — smoother, more physically plausible motion across longer clips
- Prompt adherence — complex scene descriptions translate more faithfully
- Texture and detail — fine-grained surfaces and lighting hold up better at high resolution
- Image animation consistency — in I2V, the source image’s identity is preserved more reliably through movement
Where Seedance 2.0 fights back is audio synchronization — lip sync, ambient sound timing, and overall audio-visual coherence. The 14-point gap in T2V-with-audio is real, even if narrow.
Which Should You Use?
| Use Case | Recommended Model |
|---|---|
| Best raw visual quality, no audio needed | ✅ HappyHorse-1.0 |
| Animate a photo or product image | ✅ HappyHorse-1.0 |
| Video with synchronized dialogue / narration | ✅ Seedance 2.0 |
| Multilingual audio generation | ✅ HappyHorse-1.0 |
| Open-source / self-hosted pipeline | ⏳ HappyHorse-1.0 (weights coming soon) |
| Production-ready API today | ✅ Seedance 2.0 (via Dreamina) |
Try Both on Ima Studio
You don’t need separate accounts or API keys for each model. Ima Studio gives you access to HappyHorse-1.0, Seedance 2.0, Wan 2.6, Kling, Hailuo, Sora 2, and more — all in one place.
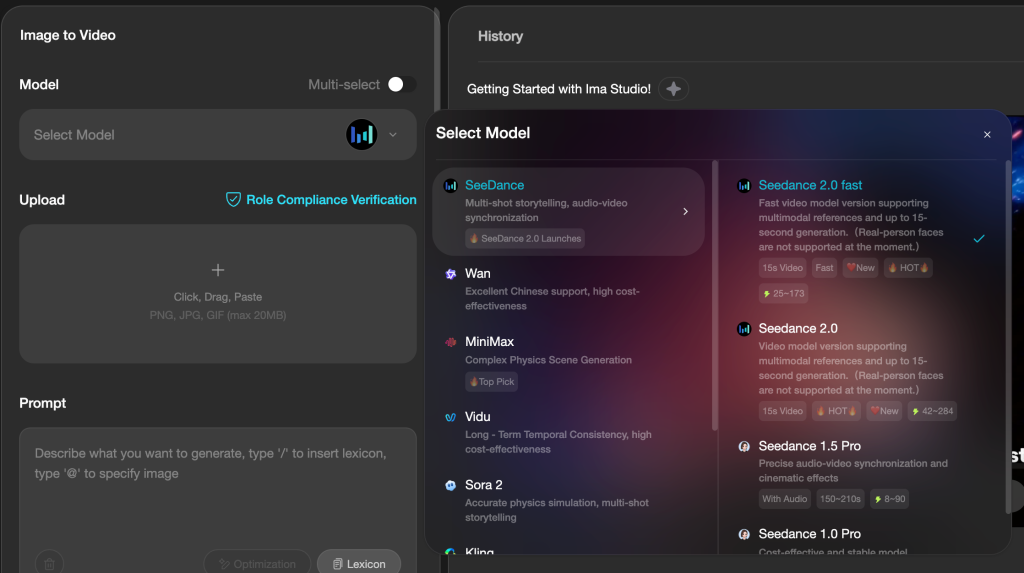
Run your own comparison. See which model works best for your specific content:
The Verdict
HappyHorse-1.0 is the better model for pure video quality — it’s not close. Seedance 2.0 retains a narrow edge in audio-video synchronization, and it has the advantage of being an established, accessible product from a known lab (ByteDance/Dreamina).
But if visual quality is your priority — and for most video creators, it is — HappyHorse-1.0 is the new benchmark. The mystery around its origins doesn’t change what the votes show.
Both models available on Ima Studio. Start your comparison now →