DeepSeek steht wieder im Rampenlicht.
Diesmal geht es um mehr als nur eine Visitenkarte.
Mit DeepSeek-V4-Pro Und DeepSeek-V4-Flash, DeepSeek bringt nicht einfach nur eine weitere Modellfamilie mit offenem Gewichtsbereich auf den Markt. Das Unternehmen versucht, drei Ideen gleichzeitig in einer Produkteinführung zu vereinen:
- ein wegweisendes Open-Source-Modell, das näher an modernste geschlossene Systeme heranreichen kann.
- Eine kostengünstigere, schnellere Variante, die sich leichter in großem Umfang einsetzen lässt.
- Und 1M-Token-Kontext weniger als Luxusfunktion, sondern eher als praktische Standardeinstellung für anspruchsvolle Arbeitslasten positioniert.
Und das ist wichtig, denn es ist nicht das erste Mal, dass das Unternehmen weltweit Aufmerksamkeit im Bereich der künstlichen Intelligenz erregt hat.
Als DeepSeeks erster Modellzyklus im Januar 2025 den Massenmarkt erreichte, wurde er zu weit mehr als nur einem weiteren Open-Source-Start. TechCrunch berichtete, dass DeepSeek aufgestiegen ist. Platz 1 im US-App-Store am 26. Januar, nachdem er gesprungen war von Nr. 31 nur ein paar Tage zuvor, und erreichte Insgesamt 2,6 Millionen Downloads im App Store und bei Google Play Am Montagmorgen berichtete TechCrunch außerdem, dass die Android-App von DeepSeek einen Hit gelandet hatte. Platz 1 im US-amerikanischen Play Store, wobei AppFigures schätzt mehr als 1,2 Millionen Downloads im Play Store und über 1,9 Millionen Downloads im App Store weltweit seit der Markteinführung.
Diese Geschichte ist wichtig, wenn man sich Folgendes ansieht DeepSeek V4.
Der Grund, warum die Leute wieder aufmerksam werden, ist nicht nur, dass V4 ein Kontextfenster mit 1 Million Token. Denn DeepSeek hat bereits bewiesen, dass es aus der KI-Blase ausbrechen und zu einer globalen Mainstream-Story werden kann.
Diese Veröffentlichung zeigt, wie schnell Open-Source-KI den Abstand zu etablierten, geschlossenen Modellen verringert – insbesondere in den Bereichen Codierung, logisches Denken und agentenbasierte Arbeitsabläufe. Für Teams, die mit KI entwickeln, ist das wichtiger als bloße Ankündigungen.
Warum die Welt wieder zuschaut
Es gibt drei Gründe, warum diese Produkteinführung sofortige Aufmerksamkeit erregt.
1. DeepSeek hat bereits eine Erfolgsgeschichte vorzuweisen.
DeepSeek ist kein unbekanntes Labor mehr. Die vorherige Veröffentlichungsphase wurde von zahlreichen Medien aufgegriffen, darunter: TechCrunch, CNBC, Forbes, Fortune, The Verge und Business Insider — nicht nur KI-native Medien.
Das verändert die Wahrnehmung einer neuen Produkteinführung. Wenn eine zuvor viral gegangene KI-Marke ein weiteres wichtiges Produkt auf den Markt bringt, wird dies nicht als “interessante Neuigkeit” betrachtet, sondern als möglicher zweiter großer Erfolg.
2. Die aktuelle Version zeigt bereits erste Anzeichen für Markterfolg.
Zum Start, der offizielle DeepSeek-V4-Pro Die Seite von Hugging Face verzeichnete ein starkes sofortiges Engagement, darunter eine große Anhängerschaft für DeepSeek und Hunderte von Likes auf der Modelseite innerhalb der ersten Stunden nach Veröffentlichung.
Genauso wichtig war, dass eine Suchprüfung direkt nach dem Start etwas Interessantes zeigte: Es erschienen bereits neue V4-Erklärungen, Landingpages und Benchmark-Zusammenfassungen in den Suchergebnissen – aber im Wesentlichen Für “DeepSeek V4 Testbericht” liegen keine Ergebnisse vor.”
Das bedeutet, dass Aufmerksamkeit schneller ankommt als qualitativ hochwertige Interpretation.
3. Die Geschichte ist umfassender als ein einzelnes Modell.
DeepSeek V4 erscheint in einem Markt, der bereits für die Entwicklung von Open-Source-Technologien, die wieder aufholen, empfänglich ist. Die neue Version fügt sich nahtlos in diese Entwicklung ein: bessere Schlussfolgerungen, längerer Kontext, höhere Relevanz der Agenten und eine gesteigerte Effizienz.
Deshalb fühlt sich das Ganze bedeutsamer an als die Veröffentlichung einer normalen Modellkarte.
Zwei Modelle, eine Strategie
Laut offizieller Pressemitteilung von Hugging Face umfasst die DeepSeek V4-Serie zwei Mixture-of-Experts-Modelle:
- DeepSeek-V4-Pro: 1,6T Gesamtparameter, 49B aktiviert
- DeepSeek-V4-Flash: 284B Gesamtparameter, 13B aktiviert
Beide Modelle unterstützen bis zu 1 Million Kontext-Tokens.
Dies ist deshalb wichtig, weil DeepSeek nicht mehr nur eine Geschichte mit einem einzigen Modell erzählt.
Interessanter zu lesen ist jedoch, dass es etwas aufbaut Zweischichtige Produktstrategie:
- Pro ist das Flaggschiff, das entwickelt wurde, um in den Bereichen logisches Denken, Codierung, kontextbezogenes Arbeiten und agentenbasierte Ausführung um Aufmerksamkeit zu konkurrieren.
- Blitz ist die Wertschicht, die kleiner, schneller und deutlich kostengünstiger für einen breiteren Einsatz konzipiert ist.
Diese Aufteilung verleiht dem Launch einen reiferen Charakter als einer typischen, auf Benchmarks fokussierten Veröffentlichung. Sie gibt Entwicklern und Teams eine realistische Wahl zwischen “bester Performance” und “bester Effizienz”, anstatt beide Ziele in ein einziges Modell zu pressen.
DeepSeek gibt außerdem an, dass V4 mehrere architektonische Verbesserungen mit sich bringt, die darauf abzielen, Long-Context-Inferenz nicht nur theoretisch, sondern auch praktisch zu ermöglichen.
Dazu gehören:
- Hybride Aufmerksamkeitsarchitektur, Kombination aus Compressed Sparse Attention (CSA) und Heavily Compressed Attention (HCA)
- Manifold-Constrained Hyper-Connections (mHC) um die Signalausbreitung über die Schichten hinweg zu verbessern
- Myon-Optimierer für ein schnelleres und stabileres Training
Laut DeepSeeks eigenen Zahlen, DeepSeek-V4-Pro nutzt in einer 1M-Token-Konfiguration lediglich 27% der Single-Token-Inferenz-FLOPs und 10% des von DeepSeek-V3.2 benötigten KV-Caches..
Das ist die Art von Verbesserung, die das Interesse von Infrastrukturteams weckt.
Hinter der Produkteinführung steckt auch eine praktische Produktgeschichte. Die offizielle API-Dokumentation von DeepSeek zeigt, dass beides deepseek-v4-flash Und deepseek-v4-pro sind über Endpunkte verfügbar, die mit OpenAI Und Anthropisch Beide unterstützen Tool-Aufrufe, JSON-Ausgabe und eine maximale Ausgabelänge von 384.000 Token. Für Entwickler ist dies von Bedeutung, da es die Integration von V4 in bestehende Anwendungen und Agenten-Stacks vereinfacht, ohne dass eine vollständige Neuentwicklung erforderlich ist.
Genauso wichtig ist, dass DeepSeek V4 bereits mit einem Migrationspfad verknüpft hat. Die älteren Modellnamen deepseek-chat Und deepseek-reasoner werden voraussichtlich am 2026/07/24, wobei die Kompatibilität sie den nicht-denkenden und denkenden Modi zuordnet. deepseek-v4-flash.
Also, wie gut ist DeepSeek V4 tatsächlich?
Wenn wir den ganzen Hype beiseite lassen und uns die offiziellen Informationen ansehen, lautet die Antwort: DeepSeek V4 macht einen wirklich starken Eindruck – insbesondere für Arbeiten mit langem Kontext, Codierung und Workflows mit hohem logischem Anspruch – sollte aber dennoch eher als vielversprechende Vorschau denn als endgültiger Gewinner betrachtet werden.
Das ist die fairste Art der Bewertung.
1. DeepSeek V4-Pro sieht aus wie ein ernstzunehmendes Open-Source-Flaggschiff.
Auf dem Papier, DeepSeek-V4-Pro-Max ist eindeutig darauf ausgelegt, mit innovativen Modellen zu konkurrieren, nicht nur mit anderen Open-Source-Veröffentlichungen.
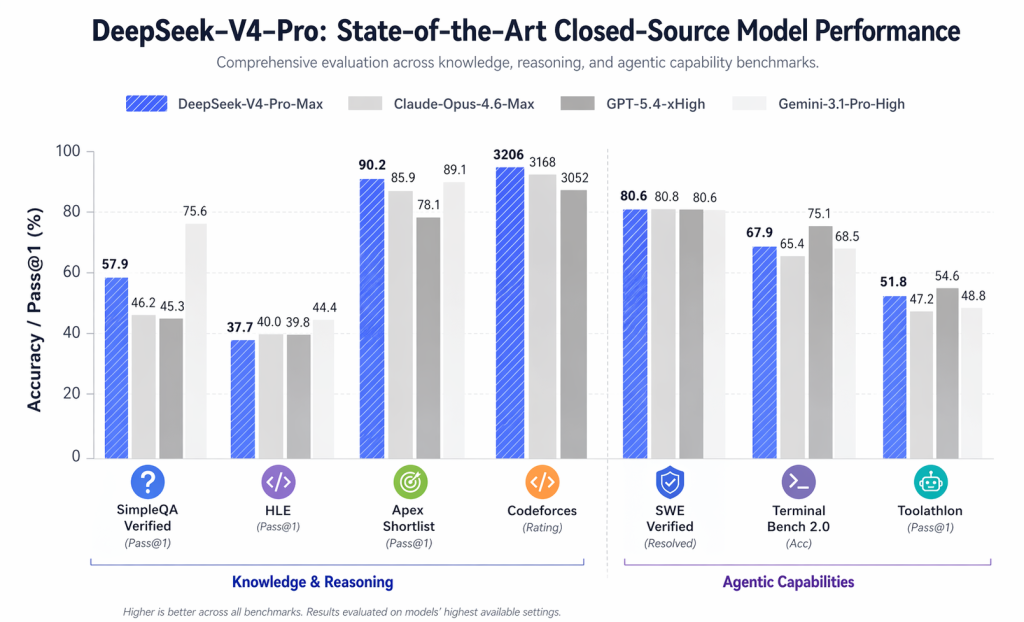
In der offiziellen Vergleichstabelle werden bemerkenswerte Zahlen veröffentlicht, wie zum Beispiel:
- LiveCodeBench: 93,5
- Codeforces-Bewertung: 3206
- GPQA Diamond: 90,1
- SWE-Verifizierung: 80,6
- MRCR 1M: 83,5
Die wichtigste Erkenntnis ist nicht, dass DeepSeek V4 alle geschlossenen Modelle in jeder Hinsicht übertrifft. Das tut es nicht. Die plausiblere Schlussfolgerung ist jedoch, dass es nun bei einer Reihe anspruchsvoller technischer Aufgaben in die gleiche ernstzunehmende Kategorie gehört.
2. Flash könnte die Überraschungsgeschichte sein
Viel Aufmerksamkeit wird der Pro-Variante zuteilwerden, aber DeepSeek-V4-Flash könnte sich letztendlich als ebenso wichtig für den kommerziellen Markt erweisen.
Laut der API-Preisseite von DeepSeek kostet V4-Flash Folgendes:
- $0.14 / 1M Eingabetoken (Cache-Fehler)
- $0.028 / 1M Eingabetoken (Cache-Treffer)
- $0.28 / 1M Ausgabetoken
Im Vergleich dazu, DeepSeek-V4-Pro ist zum Preis von:
- $1.74 / 1M Eingabetoken (Cache-Fehler)
- $0.145 / 1M Eingabetoken (Cache-Treffer)
- $3.48 / 1M Ausgabetoken
Das ergibt eine interessantere Produktgeschichte als “größeres Modell gewinnt”. Flash bietet DeepSeek eine realistische Wertschöpfungsebene für Anwendungsfälle mit hohem Volumen, während Pro die Positionierung als Flaggschiffmodell einnimmt.
3. DeepSeek möchte nicht nur die Chatbot-Konversation, sondern auch die Agentenkonversation gewinnen.
Eines der deutlichsten Signale in der V4-Version ist, worauf DeepSeek den Schwerpunkt legt.
Die offiziellen Bewertungstabellen beschränken sich nicht auf Wissens- und Denkleistungsmaßstäbe. Sie heben auch Folgendes hervor: agenten- und werkzeugnutzungsorientierte Aufgaben wie zum Beispiel:
- Terminalbank 2.0
- SWE-verifiziert
- SWE Pro
- BrowseComp
- MCPAtlas
- Toolathlon
Das ist wichtig, weil es darauf hindeutet, dass DeepSeek möchte, dass V4 als ein Agentenfertige Modellfamilie, nicht nur als Chatbot oder Programmierassistent.
Für Teams, die KI-Produkte entwickeln, ist das ein relevanteres Ziel als bloßes Schaulaufen auf der Rangliste.
4. Flash könnte die Überraschungsgeschichte sein
Viel Aufmerksamkeit wird der Pro-Variante zuteilwerden, aber DeepSeek-V4-Flash könnte sich letztendlich als ebenso wichtig für den kommerziellen Markt erweisen.
Laut der API-Preisseite von DeepSeek kostet V4-Flash Folgendes:
- $0.14 / 1M Eingabetoken (Cache-Fehler)
- $0.028 / 1M Eingabetoken (Cache-Treffer)
- $0.28 / 1M Ausgabetoken
Im Vergleich dazu, DeepSeek-V4-Pro ist zum Preis von:
- $1.74 / 1M Eingabetoken (Cache-Fehler)
- $0.145 / 1M Eingabetoken (Cache-Treffer)
- $3.48 / 1M Ausgabetoken
Das ergibt eine interessantere Produktgeschichte als “größeres Modell gewinnt”. Flash bietet DeepSeek eine realistische Wertschöpfungsebene für Anwendungsfälle mit hohem Volumen, während Pro die Positionierung als Flaggschiffmodell einnimmt.
5. Denkmodi sind ein echter Vorteil in puncto Benutzerfreundlichkeit.
DeepSeek V4 unterstützt verschiedene Schlussfolgerungsmodi, anstatt für jede Aufgabe ein einheitliches Verhalten zu erzwingen.
Das ist eine sinnvolle Produktentscheidung.
Bei Routineanfragen können Benutzer die Geschwindigkeit priorisieren. Für komplexe Planungs-, Programmier- oder Forschungsaufgaben können sie mehr Aufwand für die logische Auswertung betreiben. In der Praxis ist die Modellfamilie dadurch besser an reale Arbeitslasten anpassbar als ein einzelner statischer Inferenzstil.
6. Die stärkste Behauptung ist die Langzeitkontexteffizienz.
Viele KI-Einführungen sprechen über Kontextlänge. Nur wenige schaffen es, die Ausführung über lange Kontexte hinweg operativ glaubwürdig erscheinen zu lassen.
Hier könnte V4 am interessantesten sein.
A 1M-Token-Kontextfenster ist bereits ein Hauptmerkmal, aber das wichtigere Detail ist DeepSeeks Behauptung, dass V4-Pro nur 27% der Einzel-Token-Inferenz-FLOPs Und 10% des KV-Caches wird von DeepSeek-V3.2 in diesem Kontextmaßstab benötigt.
Wenn sich diese Verbesserungen in der Praxis bestätigen, könnte das genauso wichtig sein wie Vergleichswerte.
Warum das 1-Millionen-Token-Kontextfenster wichtiger ist, als es klingt
Ein Kontextfenster mit einer Million Token ist nicht nur eine Marketingstrategie.
In der Praxis bedeutet dies, dass Entwickler und Teams viel größere Mengen an Quellmaterial in eine einzige Sitzung einbringen können – lange Codebasen, umfangreiche Dokumentationssätze, Forschungsarchive, Kundenprotokolle oder Workflows mit mehreren Dateien, die früher umständliche Chunking-Strategien erforderten.
Das eröffnet mehrere wertvolle Anwendungsfälle:
1. Verständnis großer Codebasen
Teams können größere Repositories mit weniger manuellem Slicing analysieren, was die Arbeitsabläufe beim Debuggen, Refactoring und agentenbasierten Codieren verbessert.
2. Forschung und Wissenssynthese
Anstatt Fragmente in ein Modell einzufügen und dabei den globalen Kontext zu verlieren, können Benutzer mit wesentlich größeren Quellsammlungen auf einmal arbeiten.
3. Bessere KI-Agenten
Agentensysteme arbeiten effizienter, wenn sie mehr Kontextinformationen speichern können. Für Planung, Werkzeugnutzung und die Ausführung mehrstufiger Aufgaben ist die Kontexteffizienz fast genauso wichtig wie die reine Schlussfolgerungsqualität.
4. Dokumenten-Workflows im Unternehmen
Lange Verträge, Compliance-Dokumente, Support-Archive und interne Wikis lassen sich innerhalb einer einzigen Denkschleife besser handhaben.
Allerdings bewirkt die Kontextlänge allein schon nicht Qualität garantieren. Viele Modelle werben mit langen Zugriffszeiten, verschlechtern sich aber, sobald die Abrufqualität, der Speicherfokus oder die Latenz zum Problem werden.
Deshalb sind die Effizienzangaben von DeepSeek wohl wichtiger als die Zahl von 1 Million selbst.
Warum sich dieser Launch größer anfühlt als ein normaler Benchmark-Leak
DeepSeek positioniert V4 nicht nur als ein Modell für lange Kontexte.
Es unternimmt auch ernsthafte Anstrengungen in Argumentation, Codierung, Und Agentenleistung.
Die Highlights der Veröffentlichung DeepSeek-V4-Pro-Max als den stärksten Argumentationsmodus im Angebot und stellt ihn als eines der besten derzeit verfügbaren Open-Source-Modelle dar.
In den veröffentlichten Vergleichstabellen erzielt der V4-Pro-Max besonders starke Ergebnisse in Bereichen wie:
- LiveCodeBench
- Codeforces-ähnliche Codierungsleistung
- GPQA Diamond
- BrowseComp
- Benchmarks für Softwareentwicklung im SWE-Stil
- Langzeitkontexttests wie MRCR 1M und CorpusQA 1M
Die genauen Ranglisten werden sich weiterhin ändern, da die Labore ihre Modelle alle paar Wochen aktualisieren. Das strategische Signal ist jedoch bereits klar:
Open-Source-Modelle gewinnen zunehmend an Glaubwürdigkeit für anspruchsvolle technische Arbeitsabläufe, nicht nur für einfache Chat-Anwendungen.
Das ist der eigentliche Grund, warum dieser Start so wichtig ist.
Der interessanteste Teil: Denkmodi
DeepSeek V4 unterstützt drei Schlussfolgerungsmodi:
- Nicht-Denken für schnelle, leichte Reaktionen
- Denk hoch! für eine langsamere, überlegtere Analyse
- Denk an Max für maximalen Denkaufwand
Dies ist wichtig, weil es widerspiegelt, wohin sich der Modellmarkt entwickelt.
Die Zukunft besteht nicht nur aus “einem Modell, einem Verhalten”. Es geht zunehmend darum adaptive InferenzSchnell, wenn es auf Geschwindigkeit ankommt, tiefer, wenn es auf Genauigkeit ankommt.
Für Produktteams schafft dies ein besseres Gleichgewicht zwischen:
- Latenz
- kosten
- Argumentationstiefe
- Benutzererfahrung
Anders ausgedrückt: DeepSeek liefert nicht nur ein Modell aus. Es liefert ein Nutzungsmuster Das entspricht der Entwicklung realer KI-Produkte.
Was dies für Open-Source-KI bedeutet
DeepSeek V4 verstärkt drei übergeordnete Trends.
1. Open-Source-Software lässt sich immer schwerer ignorieren.
Die Kluft zwischen führenden offenen und geschlossenen Modellen besteht zwar weiterhin, verringert sich aber sichtbar. Jede größere Version zwingt Produktteams nun dazu, neu zu bewerten, ob sie tatsächlich für jeden Workflow ein geschlossenes Modell benötigen.
2. Effizienz wird zu einem erstklassigen Schlachtfeld
Das Modell mit der höchsten Punktzahl ist nicht automatisch das nützlichste. Im realen Einsatz bestimmen Speichereffizienz, Durchsatz und Inferenzkosten die Produktrentabilität.
3. Agenten-Workflows setzen neue Maßstäbe.
Da immer mehr Unternehmen KI-Agenten entwickeln, sind die wertvollsten Modelle diejenigen, die gleichzeitig lange Kontexte, mehrstufige Schlussfolgerungen und eine toolorientierte Ausführung bewältigen können.
DeepSeek V4 zielt eindeutig auf diese Schnittstelle ab.
Ein paar Warnungen, bevor der Hype außer Kontrolle gerät
Dies ist ein Vorschauversion, Teams sollten daher realistisch bleiben.
Ein paar Dinge sind sehenswert:
- Latenzzeiten in der Praxis unter hoher Last durch lange Kontextzyklen
- Leistungskonsistenz über verschiedene Prompt-Stile hinweg
- Zuverlässigkeit der Werkzeugnutzung außerhalb von Benchmark-Einstellungen
- Bereitstellungskomplexität für Teams, die es lokal ausführen möchten.
- Ob sich Benchmark-Gewinne in stärkeren Produktionsergebnissen niederschlagen
DeepSeek weist außerdem darauf hin, dass die lokale Bereitstellung einen eigenen Kodierungs- und Inferenz-Workflow erfordert und keine einfache Plug-and-Play-Vorlage bietet. Dies ist zwar kein Ausschlusskriterium, bedeutet aber, dass die Einführung für technisch versierte Teams einfacher sein kann als für Gelegenheitsnutzer.
Endgültige Bewertung
DeepSeek V4 ist nicht nur wegen seiner technischen Daten von Bedeutung, sondern weil es beweist, dass DeepSeek in großem Umfang globale Aufmerksamkeit erregen kann.
Deshalb schaut die Branche wieder genau hin.
Auf technischer Ebene zeichnet sich das Modell durch ein Kontextfenster von 1 Million Token, eine höhere Effizienz bei längeren Kontexten, eine verbesserte Codierungs- und Schlussfolgerungsleistung sowie eine klare Hinwendung zu agentenbasierten Arbeitsabläufen aus.
Auf dem Markt startet DeepSeek mit viel Schwung. Das Unternehmen beginnt nicht mehr bei null. Dank seines vorherigen Erfolgs genießt DeepSeek bereits weltweite Markenbekanntheit, und V4 betritt einen Markt, der aktiv nach dem nächsten glaubwürdigen Sprung im Open-Source-Bereich sucht.
Wenn Sie mit KI entwickeln, ist dies nicht einfach nur eine weitere Benchmark-Veröffentlichung. Es ist ein Signal dafür, dass offene Modelle wettbewerbsfähiger, praktischer und zunehmend bereit für den realen Produktionseinsatz werden.
DeepSeek V4 wird die Debatte um geschlossene versus offene KI vielleicht nicht beenden. Aber es setzt definitiv neue Maßstäbe dafür, was Teams im Jahr 2026 von Open-Source-KI erwarten können.
So testen Sie DeepSeek V4
Wenn Sie das selbst erkunden möchten, gibt es verschiedene Möglichkeiten, damit zu beginnen:
- Lokal ausführen (volle Kontrolle)
Herunterladen und bereitstellen über Hugging Face:
👉 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro - Sofort ausprobieren (keine Einrichtung erforderlich)
Nutzen Sie die offizielle Chat-Oberfläche:
👉 https://chat.deepseek.com/ - Integration über API (damit entwickeln)
Greifen Sie über ein einheitliches API-Gateway auf DeepSeek V4 zu:
👉 https://www.imarouter.com Sie können es problemlos in Ihre bestehenden Arbeitsabläufe oder Agententools integrieren, wie zum Beispiel OpenClaw, Claude Code, und andere Automatisierungssysteme.
Quellen
- Offizielle Produktseite: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- TechCrunch: DeepSeek löst ChatGPT als beliebteste App im App Store ab
- TechCrunch: DeepSeek erreicht Platz 1 im US-Play-Store
- CNBC: Chinas KI DeepSeek verdrängt ChatGPT aus dem App Store: Das sollten Sie wissen